この記事は、リレーブログ企画「24新卒リレーブログ」の記事です。
はじめまして。
新卒1年目でジョブローテーション中の山本です。
今回、24卒のブログリレー企画で、テーマは「自由」ということなので、私が先日Vision AI Expo 2024に参加した際に知った「roboflow」という画像認識ツールの体験記について執筆させていただきました。
AIの知識がまったくない、、、という方でも簡単に画像認識ができるツールとなっており、大学で画像認識のAIを作成していた身としてもとても衝撃を受けたツールなので、少しでも興味のある方はぜひ参考にしていただければと思います。
▼目次
roboflowの概要
roboflowとは
そもそもroboflowってなんぞやって話ですが、
公式によると
Everything you need to build and deploy computer vision models
Roboflow: Computer vision tools for developers and enterprises
とのこと。
なんかすごそうですね、、、
まあざっくりいうと、このroboflowで画像認識に必要なタスクが全てできてしまうすごいツールっていうことです。
画像認識AIモデルの作成から他ユーザとのモデルの共有、作成したモデルの品質管理などが行えるツールとなっています。
このroboflowですが、アメリカでは「AIモデル構築プラットフォーム」としてのデファクトスタンダードとなっているそうで、2022年時点で60,000ユーザを獲得し、多くの研究・開発に利用されているようです。
なぜroboflowが人気なのか
ではなぜroboflowがここまで人気なのでしょうか?
簡単にまとめると以下の4点が人気の理由です。
- 使いやすさ
- 専門知識が少なくても、GUIで高度な画像認識プロジェクトを実現できる。
- 効率性
- データの前処理からモデルのデプロイまでを1つのプラットフォームで完結できる。
- 柔軟性
- 様々な画像認識タスク(物体検出、セグメンテーション、分類など)に対応している。
- コミュニティ
- 豊富な事前トレーニング済みモデルやデータセットが利用・拡張可能。
これらの要因が組み合わさることで、roboflowは幅広いユーザーにとって魅力的なプラットフォームとなっています。初心者から専門家まで、様々なニーズや要求に応えられる柔軟性と機能性を備えているため、画像認識プロジェクトにおける強力なツールとして人気を集めているようです。
AIブームが続く中で、こういったユーザが最新技術を容易に活用できる環境を提供してくれるというのはありがたいですね!
実際にroboflowを使ってみた
では、実際にroboflowを使って、いろいろな物体の検出をやっていきます。
上記のページにアクセスすると、roboflowユーザが作成したAIモデルを検索することができます。
(※初回のみアカウント登録が必要になるため、Googleアカウントなどお好きな方法で登録してください)
モデルの選択
まずは今回使用するモデルを選んでいきたいと思います。
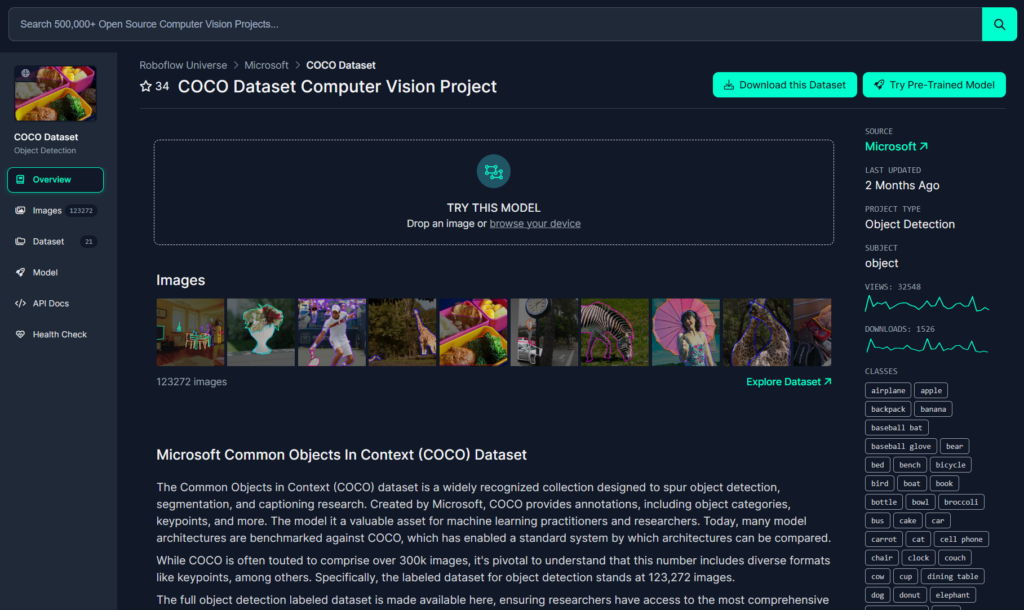
特定の物体(人や車)のみを検出するモデルなどもありますが、今回はいろいろな物体を検出してみたいので、COCO Datasetという汎用的なモデルを選択しました。
このモデルではコップや人間、猫など80種類の様々な物体検出に対応しています。対応している物体の種類に関してはOverview画面右側のCLASSESという箇所から確認することができるので、用途に合ったモデルを選択します。


デモで動作確認
roboflowではWebサイト上でどのように検出できるのかデモを行うことができる機能があるので、まずはこのモデルを試してみたいと思います。
画面左側のタブから「Model」を選択するとモデルの詳細画面に遷移します。
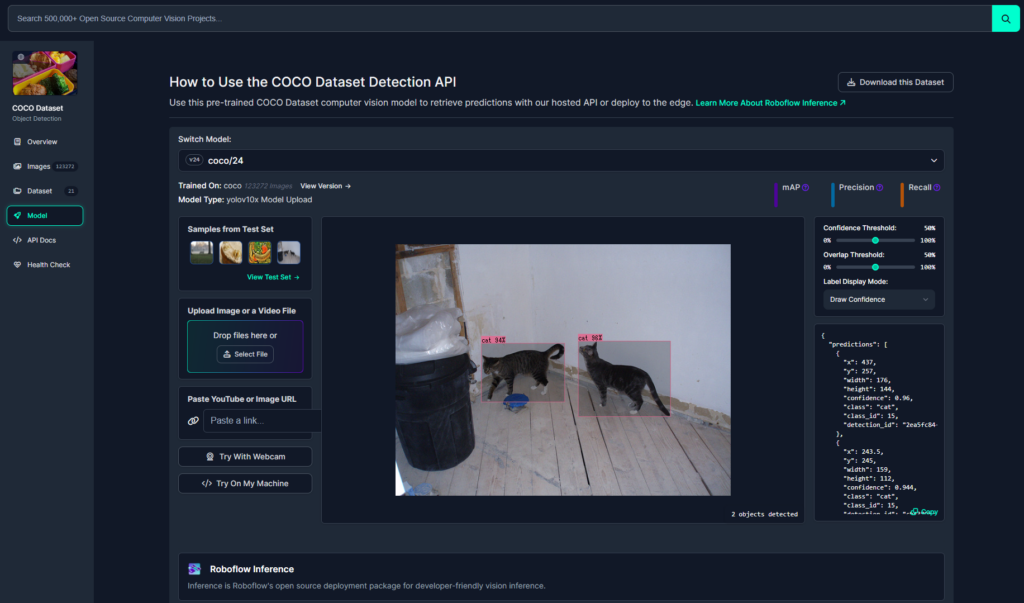
すると、さっそく画面中央に検出の結果が表示されます。

画像の選択
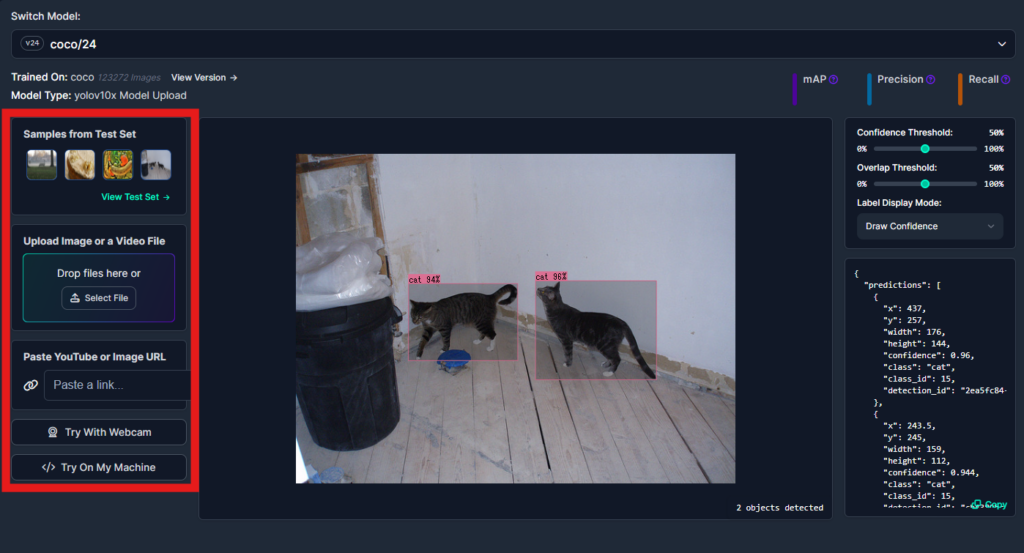
他の画像で試してみたい場合は、左の「Samples from Test Set」の箇所からすでに用意されている別の画像を選択するか、「Upload Image or a Video File」の箇所から写真や動画をアップロードすることでも確認することができます。
また、「Try With Webcam」でウェブカメラの映像からリアルタイムに検出を行うことができます。
検出の詳細設定
より細かい設定をしたい場合は
右上の「Confidence Threshold」と「Overlap Threshold」を変更することで指定できます。
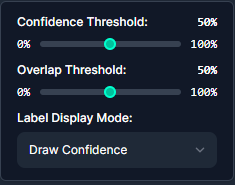
- Confidence Threshold(信頼度閾値):
- これは、AIが物体を検出したときの確信度を表します。
- 例:猫の検出
- 高い設定:AIが「100%確実に猫だ」と判断したものだけを検出します。
- 低い設定:「猫らしきもの」も検出します。例えば、猫に似た模様や形のものも含まれる可能性があります。
- 調整により、検出の精度と範囲のバランスを取ることができます。
- Overlap Threshold(重複閾値):
- これは、複数の検出結果をどう扱うかを決める基準です。
- 例:1匹の猫を複数回検出した場合
- AIが同じ猫を少しずれた位置で2回検出することがあります。
- この閾値は、「どれくらい重なっていれば、それらを1つの検出結果としてまとめるか」を決めます。
- これにより、同じ物体の重複検出を防ぎ、より正確な結果を得ることができます。
つまり、Confidence Thresholdは「検出の確信度」を、Overlap Thresholdは「検出結果をどうまとめるか」を制御する役割を果たします。これらの設定を適切に調整することで、より精度の高い物体検出が可能になります。
結果の確認
画面中央の画像から検出結果を確認することもできますが、
PythonやJavaScriptなどでAPIを利用し検出する場合は画像の右下にあるようなJSON形式で結果が取得できます。
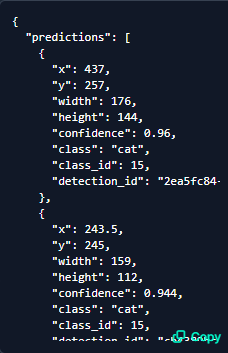
モデルの利用方法
実際に自身のプログラムでモデルを利用して検出をしていきます。
画面下のほうにスクロールすると「Code Snippets」という箇所があり、言語別に具体的な使いかたが説明されています。
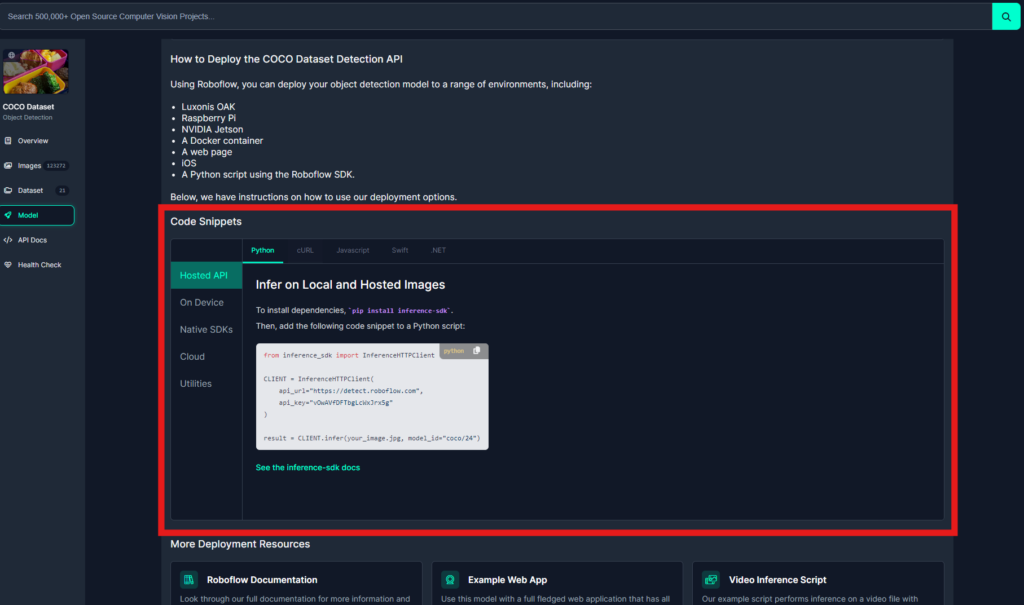
PythonのHosted APIの箇所を見ると以下のコマンドでライブラリを読み込むことができ、
|
1 |
pip install inference-sdk |
以下のコードでAPIを利用して検出ができると書いてあります。
|
1 2 3 4 5 6 7 8 |
from inference_sdk import InferenceHTTPClient CLIENT = InferenceHTTPClient( api_url="https://detect.roboflow.com", api_key="vOwAVfDFTbgLcWxJrx5g" ) result = CLIENT.infer(your_image.jpg, model_id="coco/24") |
実際に実行してみた
以下のコードを実際に実行して結果が取得できるか試してみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from inference_sdk import InferenceHTTPClient import pprint CLIENT = InferenceHTTPClient( api_url="https://detect.roboflow.com", api_key="vOwAVfDFTbgLcWxJrx5g" ) result = CLIENT.infer("input.jpg", model_id="coco/24") # 結果出力 pprint.pprint(result) |
使用した画像はこちらです↓

結果は以下のようになりました。
|
1 2 3 4 5 6 7 8 9 10 11 |
{'image': {'height': 4096, 'width': 3072}, 'inference_id': '61284435-9a72-4432-b283-2210f3e73318', 'predictions': [{'class': 'cat', 'class_id': 15, 'confidence': 0.9505542516708374, 'detection_id': 'f4b4a946-a391-4173-9cda-9782db7788bc', 'height': 2112.0, 'width': 1788.0, 'x': 1910.0, 'y': 2472.0}], 'time': 0.6150403930000721} |
結果を見ると、
|
1 |
'class': 'cat' |
となっているので、しっかりと猫が1匹検出されているのがわかります。
ただ、JSONで結果を取得するだけではわかりづらいのでコードを少し変更して、結果を画像に描画してみました。(OpenCVを利用)

正しく検出できていそうです!
▼描画に使用したコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
from inference_sdk import InferenceHTTPClient, InferenceConfiguration import pprint import cv2 import sys # 信頼度の閾値 CONFIDENCE = 0.5 # 画像パスを実行コマンドから取得 image_path = sys.argv[1] if len(sys.argv) > 1 else "input.jpg" # 詳細設定 custom_configuration = InferenceConfiguration( # モデルの信頼度の閾値 confidence_threshold=CONFIDENCE, # クライアントのダウンサイジングを無効にする client_downsizing_disabled=True ) # InferenceHTTPClientの初期化 CLIENT = InferenceHTTPClient( api_url="https://detect.roboflow.com", api_key="vOwAVfDFTbgLcWxJrx5g" ) # 座標系の修正 def convert_coordinates(prediction, image_width, image_height): """ roboflowとcv2の座標系を変換する関数 Args: prediction (dict): 座標を含む予測結果の辞書。 image_width (int): 画像の幅。 image_height (int): 画像の高さ。 Returns: tuple: 変換された座標 (x, y, width, height)。 """ x = prediction["x"] - prediction["width"] / 2 y = prediction["y"] - prediction["height"] / 2 width = prediction["width"] height = prediction["height"] # 座標を整数に変換し、画像の範囲内に収める x = max(0, min(int(x), image_width - 1)) y = max(0, min(int(y), image_height - 1)) width = max(1, min(int(width), image_width - x)) height = max(1, min(int(height), image_height - y)) return x, y, width, height # 推論の実行 with CLIENT.use_configuration(custom_configuration): # 画像の読み込み image = cv2.imread(image_path) # ファイルが存在しない場合にエラーを出力 if image is None: print("Error: Image file not found.") sys.exit(1) # 推論の実行 result = CLIENT.infer(image, model_id="coco/24") # 結果の出力 pprint.pprint(result) # クラス・バウンディングボックスの描画 for prediction in result["predictions"]: x, y, width, height = convert_coordinates(prediction, image.shape[1], image.shape[0]) class_name = prediction["class"] confidence = int(prediction["confidence"] * 100) put_text = class_name + " " + str(confidence) + "%" cv2.rectangle(image, (x, y), (x + width, y + height), (0, 255, 0), 10) cv2.putText(image, put_text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 5, (0, 255, 0), 10) # 描画結果を保存 cv2.imwrite("result.jpg", image) |
ちなみに、上記のコードではconfidence(信頼度)を指定できるようにしているので、閾値を0.2に変更してみると、以下の画像のように結果が変わりました。

ピントが合わずにボケている人物の箇所もしっかりとpersonと認識されています。
これは信頼度が低い(ボケていて人間かどうか微妙なライン)の箇所もconfidenceの閾値を下げることで検出結果に含まれるようになったということです。
以下に他の画像の検出結果もまとめました。

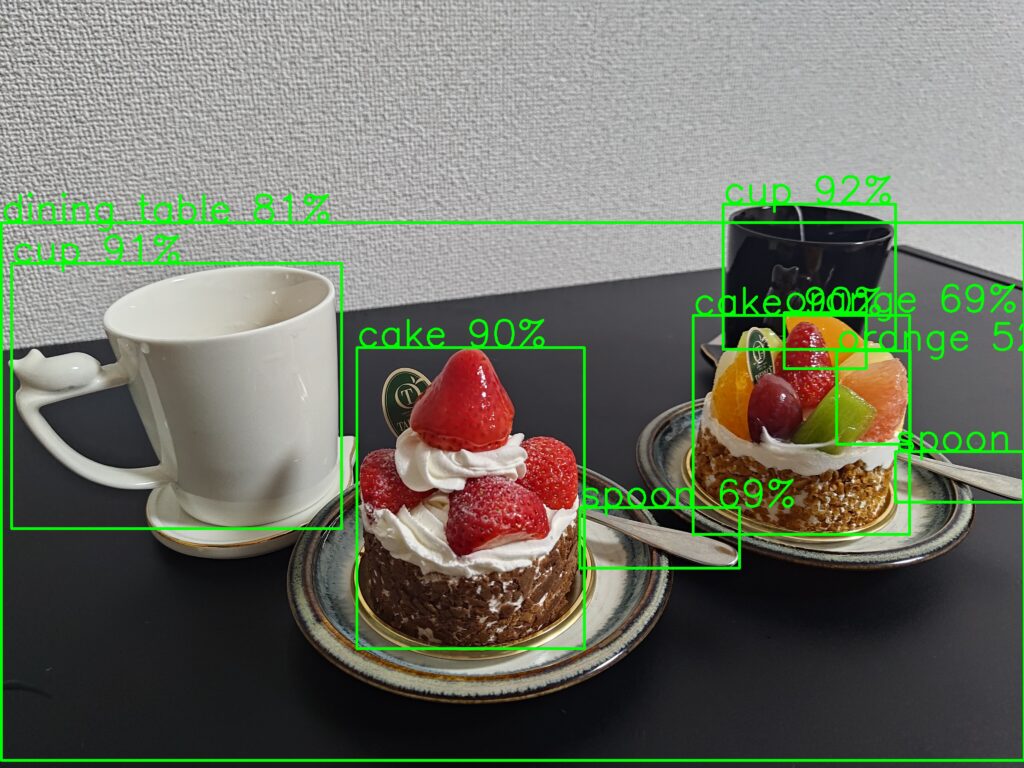


このモデルが対応している物体に関しては正確に検出ができていますね!
まとめ
このようにroboflowを利用することで少ないコードで画像認識ができてしまいます。
今回は様々な物体の検出に対応したモデルを利用しましたが、人の顔を検出するモデルを利用して顔の箇所にモザイクを入れたり、来客数を継続的に計測し販売戦略を立てたりなど、アイデア次第では様々な活用が期待できますね。
また、roboflowにはまだまだ多くの機能があります。
今回使用したCOCO Datasetはハムスターの検出に対応していませんが、追加でハムスターを検出させたい場合、自身で作成したワークスペースに、COCO Datasetのモデルをインポートして、そこにハムスターのデータを追加することでモデルを拡張することが可能です。
新たなデータを追加する際にも自動でアノテーションをしてくれる機能などもあります。
他にも動画から写真を切り出して、自動でアノテーションをしてくれたり、作成したモデルの品質管理をしてくれたりなど魅力的な機能が多く備わっています。
今後、AI技術がますます身近になっていく中で、roboflowのような手軽にAIモデルに触れることのできるツールの存在は、イノベーションを加速し、さらなる発展に寄与していくと思います。もしこの記事で少しでも興味を持っていただけた方は、ぜひビジネスや研究、個人利用など様々な場面でroboflowの活用を検討してみてください!
次回は、塚崎さんです。
どんな記事になるのかワクワクですね♪