ニフティキッズの開発担当をしている渡邊です。
3/24にニフティが運営する子ども向けサイト「ニフティキッズ」にて、AIイベントを開催しました。
当日は新宿本社に10組の親子を招き、AIについて学んでいただきました。
詳細に関してはPR TIMESの記事をご確認ください。
今回は、ニフティキッズのマスコットキャラクターである「ひよりん」と会話ができるAIひよりんの裏側を話していきます。AIひよりんはイベント用に新しく作成しました。
システム構成
AIひよりんは、ユーザーが入力したテキストに対して「ひよりん」として応答したり、指示に基づいて画像を生成したりするWebアプリケーションです。返答されたテキストは音声合成により読み上げられます。
全体的なアーキテクチャは以下の要素で構成されています。
- フロントエンド: ユーザーインターフェースを提供し、バックエンドAPIと通信。
- バックエンドAPI: ビジネスロジックを処理し、外部サービス(生成AI、音声合成)と連携。
- 生成AI: テキスト生成と画像生成を行う(Amazon Bedrockを利用)。
- 音声合成: 生成されたテキストを音声に変換(VOICEVOXを利用)。
- インフラ: アプリケーションの実行環境を提供(AWS App Runner, API Gateway, Lambda, S3などを利用)。
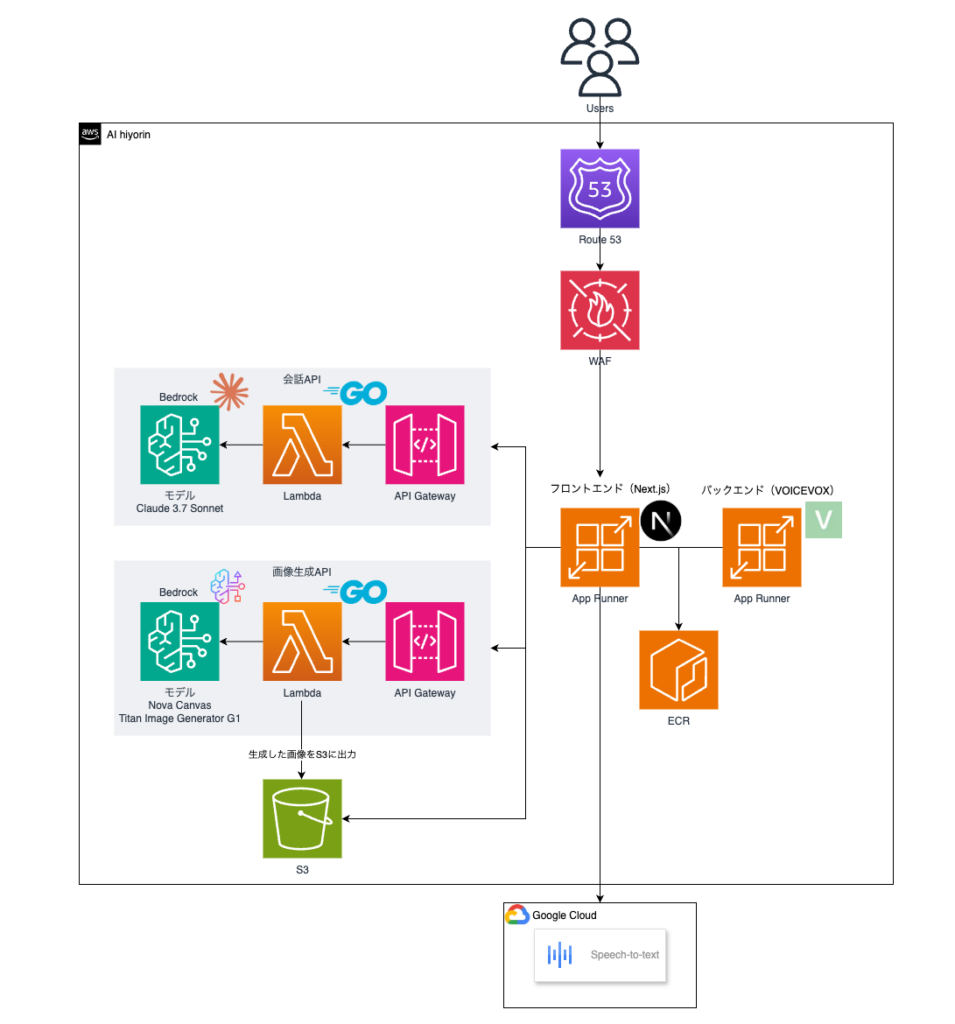
インフラ
イベント開催まで限られた時間でしたので、柔軟な開発とスムーズなデプロイを実現できるアーキテクチャを目指しました。そのため、インフラ構築や管理のオーバーヘッドが少ないAWSのマネージドサービスを積極的に活用しました。
- アプリケーション実行環境
- バックエンドAPIサーバーやVOICEVOXサーバーのホスティングには、AWS App Runnerを選定しました。
- App Runnerの詳細については、以前執筆したこちらの記事もご参照ください。
- APIエンドポイント
- フロントエンドからのリクエストを受け付けるAPIエンドポイントは、API GatewayとLambdaを用いてサーバーレス構成で構築しました。Lambda関数内で、後述するAmazon BedrockのAPIを呼び出しています。
- 画像ストレージ
- AIによって生成された画像は、Amazon S3に保存されます。保存後、フロントエンドで画像を表示するために、署名付きURLを発行する仕組みとしました。
- 音声入力
- 音声入力には、Google Cloudが提供するSpeech-to-Textを利用しました。このサービスはAPI経由で利用するため、インフラ管理は不要です。
生成AI
テキスト生成と画像生成のコアとなるAI機能には、様々な基盤モデルをAPI経由で利用できるAmazon Bedrockを採用しました。
- テキスト生成 (チャット)
- AIひよりんとの対話機能には、Anthropic社のClaude 3.7 Sonnetを利用しました。
- 開発当初、より高速なClaude 3.5 Haikuモデルも検証しましたが、AIひよりんのキャラクター設定(話し方、性格など)をプロンプトで指示した際に、Sonnetモデルの方がより忠実に、かつ自然な応答を生成することができたため、最終的にSonnetを採用しました。
- 画像生成
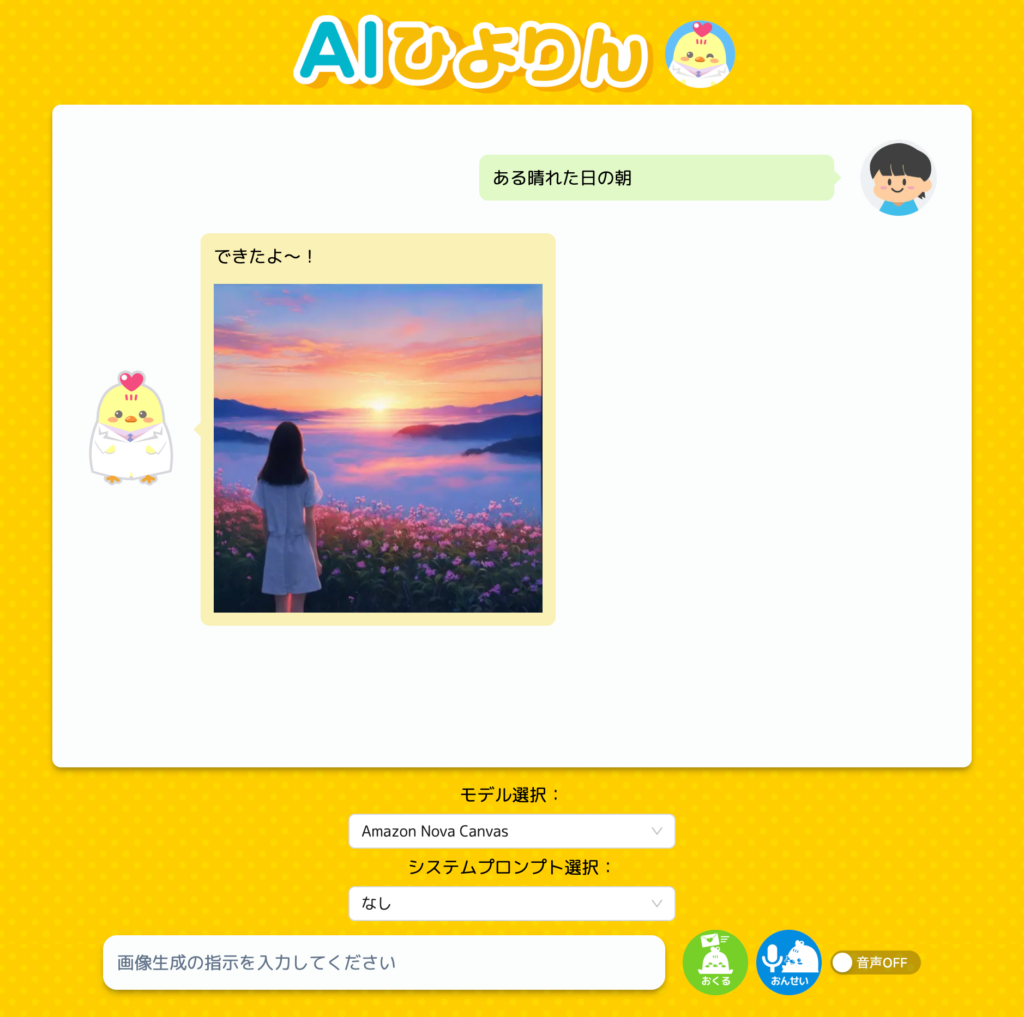
- モデル間の品質比較を行うため、Amazon Nova CanvasとTitan Image Generator G1を選べるようにしています。
バックエンドAPI
フロントエンドと各種AIサービス間のバックエンドAPIは、Go言語で実装しました。主な役割は以下の通りです。
- フロントエンドからのリクエスト(対話テキスト、画像生成指示)を受け付ける。
- リクエスト内容に基づき、Amazon BedrockのAPIを呼び出してテキスト生成や画像生成を実行する。
- 必要に応じてVOICEVOXサーバーにリクエストを送り、テキストの音声データを取得する。
- 生成されたテキスト、画像(のURL)、音声データをフロントエンドに返す。
APIとしては、主に以下の2種類を実装しました。
- 対話用API: ユーザー入力と会話履歴を受け取り、Bedrock (Claude) で生成された応答テキストと、VOICEVOXで生成された音声データを返す。
- 画像生成用API: 画像生成指示のテキストを受け取り、Bedrockで生成された画像のS3 URLを返す。
Go言語を選定した理由は実行速度の速さ、静的型付けによる堅牢性、並行処理の容易さなどです。
音声合成
AIひよりんが生成したテキストメッセージを、よりキャラクターらしく自然な音声で読み上げるために、オープンソースの高品質な音声合成ソフトウェアであるVOICEVOXを利用しました。
- 今回はDockerコンテナ版のVOICEVOXを採用し、バックエンドAPIサーバーと同様にApp Runner上でホスティングしました。
- これにより、音声合成機能を独立したマイクロサービスとして運用でき、インフラ管理の負担を軽減しつつ、スケーラビリティも確保することができました。
- バックエンドAPIは、このVOICEVOXサーバーに対してHTTPリクエストを送ることで音声データを取得します。
フロントエンド
Next.jsを用いて構築しました。主な機能は以下の通りです。
- ユーザーがAIひよりんへのメッセージを入力するテキストボックス。
- AIひよりんからの応答テキストの表示。
- 生成された画像の表示。
- 音声を再生する機能。
- バックエンドAPIとの非同期通信(対話、画像生成リクエスト)。
- ブラウザのMediaRecorder APIを利用した音声録音・データ取得処理。
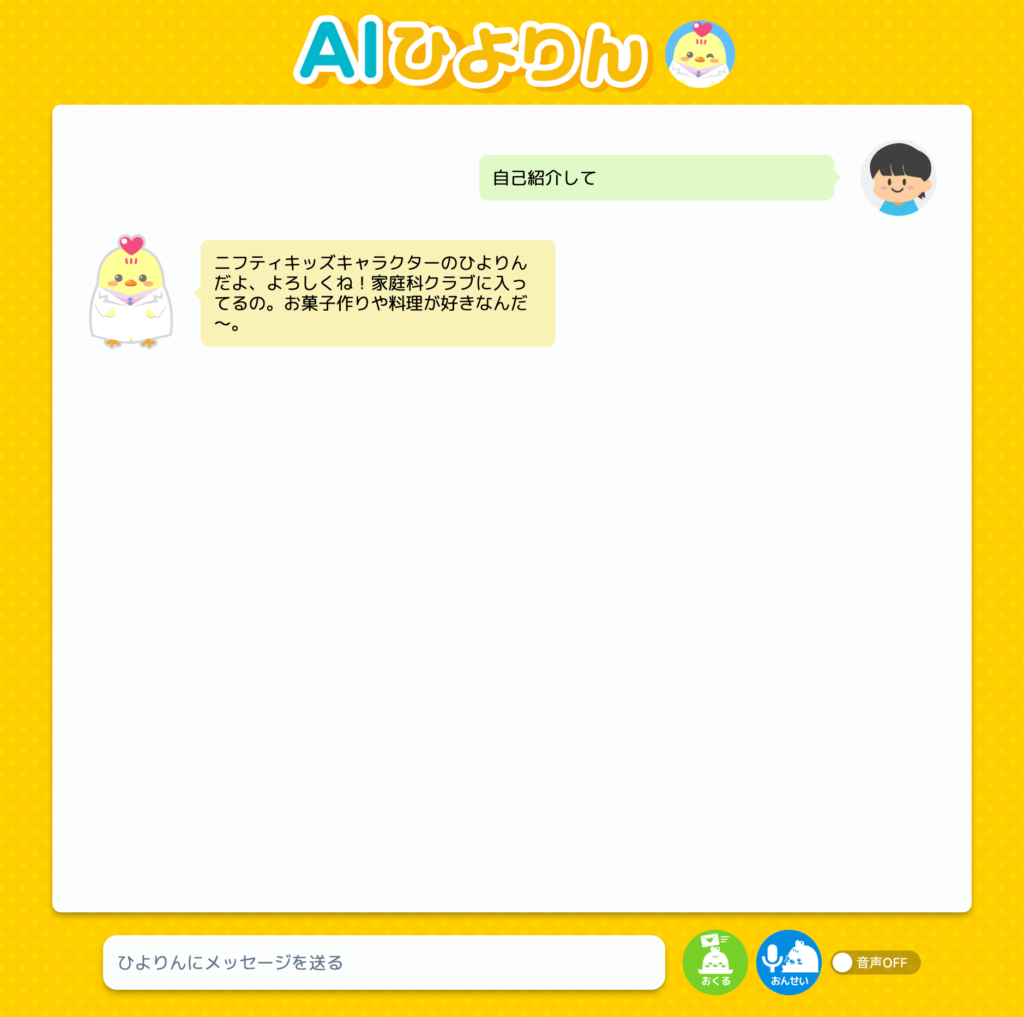
出来上がったもの
チャット
画像生成
まとめ
今回のAIひよりん開発プロジェクトでは、Amazon Bedrockを中心としたAWSのマネージドサービスと、VOICEVOXのようなオープンソースソフトウェアを組み合わせることで、短期間で子どもたちに楽しんでもらえるAIアプリケーションを実現することができました。
特に、App RunnerやLambda、API Gatewayといったサービスを活用することで、インフラ構築・管理の工数を大幅に削減し、アプリケーションロジックとAI連携部分の開発に集中できたことが、迅速なリリースにつながったと考えています。








