はじめに
始めまして、こんにちは!新卒一年目の石田と申します。
【筆者プロフィール】
- 入社時期:2025年4月
- 入社前のスキル:Python・ネットワーク・AWS未経験
- 所属チーム:インフラシステムチーム
現在私は、クラウドコストの管理を目的として、コストを取得・整形するシステムの構築に携わっています。
今回は、本システムについて、業務紹介を交えながらまとめていきたいと思います。
また、本システムはAWS上に構築していますが、私は入社するまでAWSにほとんど触れたことがありませんでした。そんな私が設計から実装までを取り組む中で、得た学びや気づきもまとめています。
今後AWSに取り組もうと考えている方、特に私と同じように未経験からスタートする皆さんの参考になれば幸いです。
クラウドコスト管理業務
現在ニフティでは、複数のクラウドサービスを利用しています。
私たちのチームでは、クラウドサービスで発生したコストを取得・加工することで、会計処理に必要となるフォーマットに整形しています。
加工の主な処理としては、以下のようなものがあります。
- 円建てコストの算出(ドル建てコストとTTSレートの乗算)
- 配賦処理(クラウドアカウントと社内部署情報との紐づけ)
- 会計用フォーマットへの適合
私の配属当時、こうした会計用ファイルの作成フローに手作業が多く、多くの工数が発生していました。また、複雑なコストを手動で整理するので、人的ミスのリスクも存在していました。
今回私は、上記課題を早期に解決するためのエンハンスに取り組みました。
システムについて
今回作成するシステムは、AWSのコストを取得し、会計用ファイルを出力するシステムです。
コスト取得・加工作業を自動化することで、工数の削減および手作業によるミスの防止を実現します。
本システムはAWS上で構築し、既存のAWSリソースも活用しながら進めます。
処理フロー
本システムの処理は、大きく3つのステップに分けられます。
①AWSのコストデータを取得
②データを加工し、会計処理に必要なフォーマットに整形
③ExcelファイルとしてS3に格納
リソース
使用したAWSリソースは以下の通りです。
S3
AWSを代表するクラウドストレージサービスで、ファイルを「オブジェクト」として保存します。
安価に、大量のデータを保管できます。
Athena
Athenaは、SQL文を使ってS3のデータを直接分析できるクエリサービスです。
後述するGlueが作成したデータカタログを参照することで、S3のどのフォルダに、どのようなデータ形式のファイルがあるかを把握します。
Glue
Glueは、サーバーレスなデータ統合サービスです。対象データの種類を自動的に特定し、データカタログを作成します。Athenaは、このデータカタログを参照することで、S3に保存されているデータを直接クエリできるようになります。
DynamoDB
DynamoDBは、柔軟なデータ構造を持つNoSQLのデータベースサービスであり、目的のデータに対してミリ秒単位での高速アクセスが可能です。
Lambda
Lambdaは、サーバーの管理なしでコードを実行できる、サーバーレスなコンピューティングサービスです。
特定のイベント(例:S3へのファイルのアップロード・API Gatewayへのリクエストなど)をトリガーとして自動的にコードが実行されます。今回は、データの取得から加工・ファイルの格納などの処理をLambda関数として実装しました。
Secrets Manager
Secrets Managerは、認証情報やAPIキーなどの機密情報を安全に管理できるサービスです。
コードに直接記述(ハードコーディング)するとセキュリティリスクが高まるような機密情報を一元管理し、コードから安全に取得できます。
構成図
先述したサービスを使用して、システムを構築していきます。
アーキテクチャ図を以下に示します。
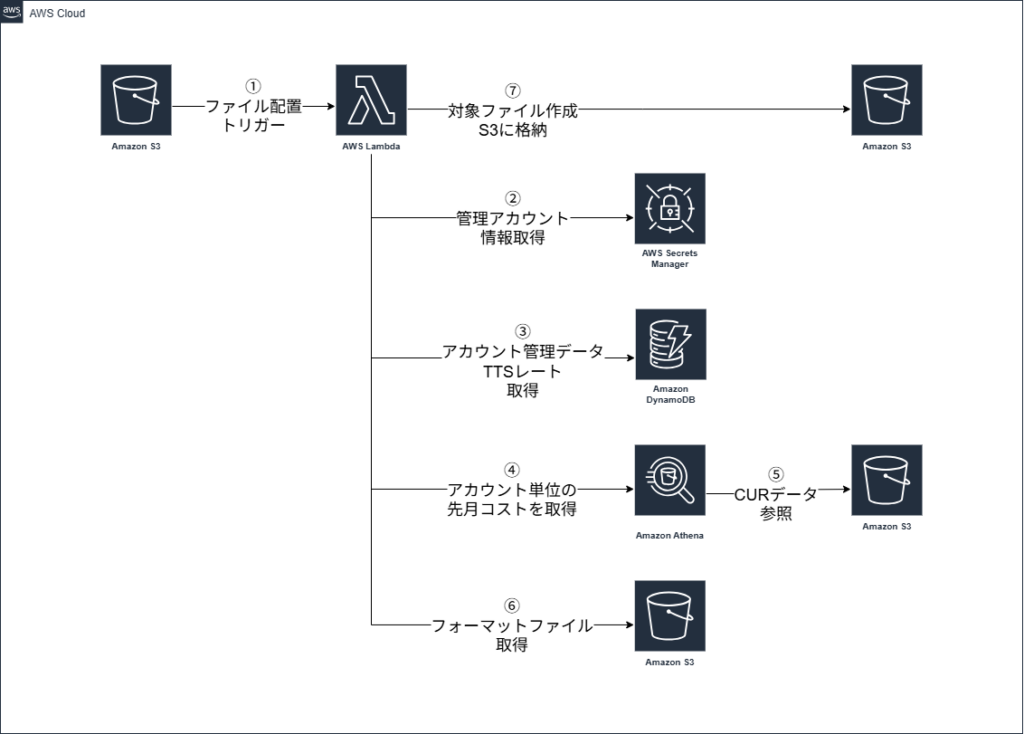
注意点としては、Lambdaのトリガーは別LambdaからのS3へのファイル配置となっています。加えて、コストもAWSから直接APIで取得するのではなく、CUR(Cost and Usage Report)[1]が自動で出力されているS3を参照する構成になっています。
コスト取得
では、実際の処理の流れを追っていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
sql_path = os.path.join(os.path.dirname(__file__), 'aws_cost.sql') with open(sql_path, 'r', encoding='utf-8') as f: query = f.read() query = query.replace('{{year}}', str(year)) query = query.replace('{{month}}', str(month)) query = query.replace('{{tts_rate}}', str(tts_rate)) raw = wr.athena.read_sql_query( query, database="test_db", ctas_approach=False, boto3_session=master_session ) |
コスト(CUR)は、管理アカウントのS3に格納されています。
SQLのクエリファイルを読み込み、管理アカウントのセッションを利用してAthenaテーブルを参照します。
これによって、アカウントやサービス単位の細かい請求データを取得できます。
コスト整形
取得したデータをDF(DataFrame)に格納して、集計・加工処理に進みます。
集計
請求書ID、請求元情報、アカウントIDでグルーピングして、各合計コストを求めます。
部門情報の結合
各AWSアカウントがどの部署の管轄かを示す部門情報を結合し、配賦対応に役立てます。
DFのExcelファイル書き込み
さて、必要なデータはそろったので、ここからは各ファイルで必要なデータを抽出する段階です。
作成する会計用Excelファイルは4つ。その内2つは、関数等が組み込まれたフォーマットファイル内の所定の位置にデータを転記する必要があります。
ここで私は、PythonコードでExcelファイルを操作できる、openpyxl[2]の使用を考えていました。
OpenPyXLは、Python上でExcelファイルを直感的に操作できる便利なライブラリです。以下のコードのように、Excelファイルを取り込んで、セルを指定して書き込みや読み込みを行えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
format_path = '/tmp/rpa_format.xlsx' output_path = '/tmp/sample1.xlsx' start_row = 11 start_col = 4 wb = openpyxl.load_workbook(format_path) ws = wb["シート1"] ws['I2'] = '会計コード' ws['I4'] = 'インフラ部門' for i, row in enumerate(sample1_df.values): for j, value in enumerate(row): cell = ws.cell(row=start_row + i, column=start_col + j) cell.value = value wb.save(output_path) |
6~8行目のようにセルを直接指定することも、9~12行目のようにfor文を回すことで、所定の位置(D11)から1セルずつ書き込むことも可能です。
さっそく実行してみます。
|
1 2 3 4 5 6 |
REPORT RequestId: cfc5c952-37f3-4d2f-bfac-c5fa22fd7438 Duration: 300000.00 ms Billed Duration: 300000 ms Memory Size: 256 MB Max Memory Used: 256 MB Status: timeout |
timeoutエラーが発生しました。メモリが足りなかったようです。
メモリを増やすと、、、
|
1 2 3 4 5 6 |
REPORT RequestId: 5377a577-dd9b-47a4-b938-48b8f77efa1c Duration: 21806.13 ms Billed Duration: 21807 ms Memory Size: 2048 MB Max Memory Used: 584 MB Init Duration: 5069.78 ms |
問題なく処理完了できました。 今回はメモリの増量で対応しましたが、処理自体をもっと軽くしたい場合には「lxml[3]」というライブラリも存在します。
OpenPyXLは、Python上でExcelファイルを直感的に操作できる便利なライブラリですが、Excelファイルを構成するXMLファイル全体をメモリに読み込む特性上、大量のデータを扱う際にはメモリ不足やタイムアウトの原因になることがあります。
対してlxmlは、ストリーミング処理に対応しており、ファイル全体をメモリに読み込むことなく、必要な部分だけを順次処理することで、メモリ使用量を抑えつつ高速なデータ処理を可能にします。
しかし、一度試してみたところ、出力ファイルが壊れてしまいました。
原因を調査したかったのですが、スケジュールの都合上見送りました、、、
ファイル出力
出力
何はともあれ、会計用ファイルが完成しました!S3にアップロードしていきます。
|
1 2 3 4 5 6 7 8 9 10 |
sample_files = [ ('/tmp/sample1.xlsx', f's3://{INVOICE_BUCKET_ID}/sample/year={year}/month={month}/sample1.xlsx'), ('/tmp/sample2.xlsx', f's3://{INVOICE_BUCKET_ID}/sample/year={year}/month={month}/sample2.xlsx'), ('/tmp/sample3.xlsx', f's3://{INVOICE_BUCKET_ID}/sample/year={year}/month={month}/sample3.xlsx'), ('/tmp/sample4.xlsx', f's3://{INVOICE_BUCKET_ID}/sample/year={year}/month={month}/sample4.xlsx'), ] for local_file, s3_path in sample_files: wr.s3.upload(local_file=local_file, path=s3_path) |
パスを指定し、作成したExcelファイルをアップロードしています。
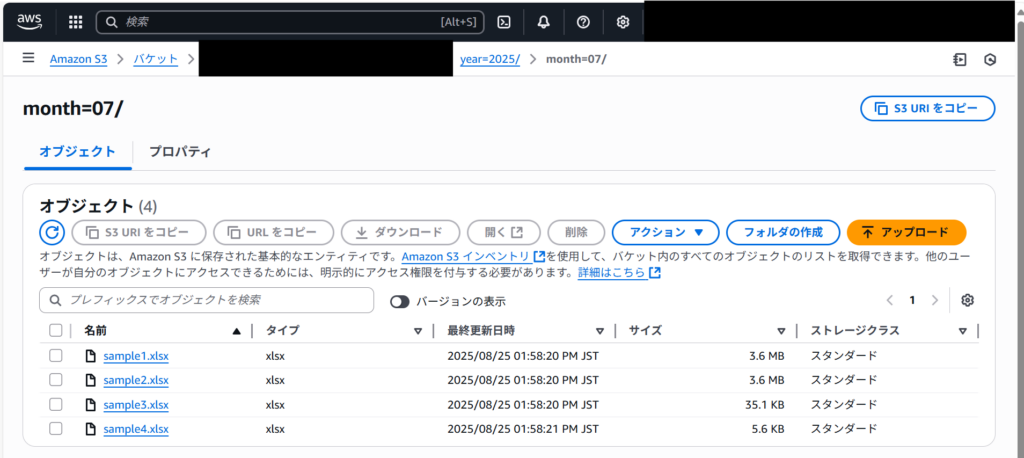
問題なくアップロードできました!これにて処理完了となります。
まとめ
今回私は、ほぼ単独でシステムの設計から実装までを担当させていただきました。AWSの基礎サービスを学びながら進める中で、特にIAMによるアクセス制御と、S3・Athena・Glueの関係性の理解に苦労しました。
当初はより多くの機能や、他クラウドへの対応も計画していましたが、思うように作業が進まず、スケジュールが大幅にずれ込みました。そこで、機能に優先順位をつけ、重要な部分から実装を進めることで、なんとか完成にこぎつけることができました。
そのような反省点がありつつも、AWSについて学び、上流から下流まで一通りの開発工程を経験できたことは、大きな収穫でした。この経験を活かし、今後のOJT業務に臨んでいきたいと思います。
学生の皆様に向けて
入社して約5か月が経ちますが、ニフティは「繋がり」を大切にしている会社であると強く実感しています。
お客様やパートナー企業様との繋がりはもちろんのこと、社員と企業、また社員同士の繋がりが非常に強いです。部署を超えたコミュニケーションや社内イベントも非常に活発に行われています。
同じ会社にいても、チームによって雰囲気や文化が大きく異なるのも面白いところです。コミュニケーションが活発なチームもあれば、効率を重視するチーム、社内イベントに積極的に参加するチームなど様々です。
一口に「エンジニア」と言っても、多様な個性を持つメンバーがそれぞれの強みを活かして業務に取り組んでいます。
ニフティの雰囲気をもっと知りたいという方は、ぜひインターンシップにご参加ください。皆さんとお会いできるのを楽しみにしています!
次回はついに最終走者!
やまだ25さんの記事をお楽しみに!!