はじめに
はじめまして。ニフティ新卒4年目の内海です。 社内でSRE活動が浸透し始めており、その活動の一環としてSLI/SLOという概念を利用したサービスの信頼性を可視化する動きが広まっています。 本題に入る前に簡単にSLI/SLOについてご説明したいと思います。SLI (Service Level Indicator)
日本語ではサービスレベル指標と要約できますが、一般的には以下の指標を利用することが多いです。- 可用性
- エラー
- システムスループット
- リクエストのレイテンシ
対象サービス (機能)の30日間のリクエスト成功率が99.9%
のようなイメージです。 可用性とはシステムが継続して稼働できる能力のことです。サービス提供が不可能になる時間が少なく、安定して利用することができるサービスは可用性が高いと言えます。つまり、可用性が高いサービスは信頼性が高いサービスであると言えます。SLO (Service Level Objective)
SLIの説明で挙げた各指標に対しての目標数値になります。 例えば対象サービス (機能)の30日間のリクエスト成功率が99.9%
のように99.9%という具体的な数値目標がSLOになります。 SLI/SLOを設定するメリットとしては以下が挙げらます。サービス品質の見える化のため
SLI/SLOを設定することで「お客様がサービスを利用できているか」が数値として可視化されるようになります。サービスの状態が明確に分かるようになり、お客様への影響が素早く発見できるようになります。SLOドリブンな開発を行うため
SLOを設定することでSLOを上回っている場合は継続的な開発を行い、SLOを下回っている場合は開発をストップして信頼性の改善を行うといったように、どちらを優先すべきか判断することができます。具体的にはSLOに基づいて算出されるエラーバジェットによって決まります。 エラーバジェットとは「サービスの信頼性がどの程度損なわれても許容できるか」を示す指標になります。例えばSLOを99.9%と定義した場合は0.1%がエラーバジェットになります。100% – SLO(99.9%) = 0.1%
時間に直すと1ヶ月を30 日間とした場合の許容ダウンタイムは 43 分です。 1ヶ月の内、ダウンタイムが43分未満であれば開発を行い、43分を超えた場合に開発を中断してダウンタイムを減らすことに注力するといったイメージです。目的
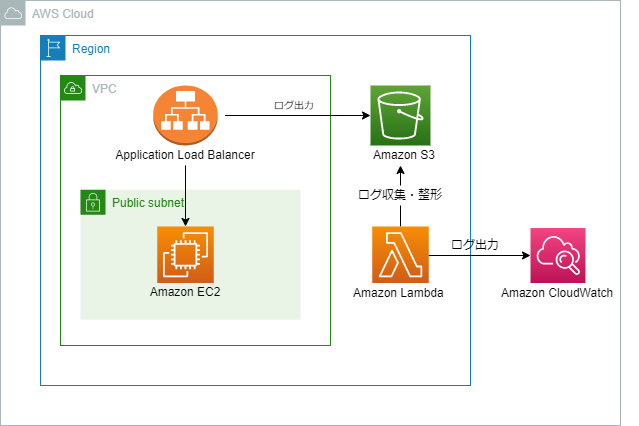
本記事ではある特定のページに対しての可用性がどの程度かをApplication Load Balancerのログを利用して可視化する手順をご紹介します。可用性を可視化してサービスの信頼性を計測することが目的です。構成図
基本的には以下の構成を前提としています。- WEBサーバーの手前に Application Load Balancer が配置されている
- Application Load BalancerのアクセスログがS3に保存されている
- ALBのアクセスログをS3に保存する設定は公式ドキュメント に記載されています。
利用するAWSサービスの紹介
Amazon Simple Storage Service (Amazon S3)
Amazon Simple Storage Service (Amazon S3) は、業界をリードするスケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービスです。ALBのログの格納先として利用します。引用 – https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/Welcome.html
AWS Lambda
Lambda はサーバーをプロビジョニングしたり管理しなくてもコードを実行できるコンピューティングサービスです。Lambdaを利用してS3に格納されているアクセスログを抽出・整形します。引用 – https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/welcome.html
Amazon CloudWatch
AWSが提供するフルマネージド運用監視サービスになります。CloudWatchに搭載された以下の機能を利用して可視化を実現します。メトリクスフィルタ
ログデータから特定の文字列をフィルタリングする機能です。 Lambdaでアクセスログを抽出・整形したログがCloudWatch Logsに出力されるようになっているので、ログをフィルタリングしてメトリクスを作成します。Amazon CloudWatch ダッシュボード
CloudWatchダッシュボードを使用することでAWS リソースのメトリクスを表示することができます。メトリクスフィルタによって作成されたメトリクスを可視化させる際に利用します。作成手順
Lambdaの作成
S3に格納されているアクセスログを抽出・整形を行うLambda関数を作成します。|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
import json import re import boto3 import logging import gzip from urllib.parse import urlparse RE_TEXT_ALB = r""" ^(?P<type>[^ ]*)\u0020 (?P<time>[^ ]*)\u0020 (?P<elb>[^ ]*)\u0020 (?P<client_ip>[^ ]*):(?P<client_port>[0-9]*)\u0020 (?P<target_ip>[^ ]*)[:-](?P<target_port>[0-9]*)\u0020 (?P<request_processing_time>[-.0-9]*)\u0020 (?P<target_processing_time>[-.0-9]*)\u0020 (?P<response_processing_time>[-.0-9]*)\u0020 (?P<elb_status_code>|[-0-9]*)\u0020 (?P<target_status_code>-|[-0-9]*)\u0020 (?P<received_bytes>[-0-9]*)\u0020 (?P<sent_bytes>[-0-9]*)\u0020 \"(?P<request_method>[^ ]*)\u0020 (?P<request_url>[^ ]*)\u0020 (?P<request_http_version>- |[^ ]*)\"\u0020 \"(?P<user_agent>[^\"]*)\"\u0020 (?P<ssl_cipher>[A-Z0-9-]+)\u0020 (?P<ssl_protocol>[A-Za-z0-9.-]*)\u0020 (?P<target_group_arn>[^ ]*)\u0020 \"(?P<trace_id>[^\"]*)\"\u0020 \"(?P<domain_name>[^\"]*)\"\u0020 \"(?P<chosen_cert_arn>[^\"]*)\"\u0020 (?P<matched_rule_priority>[-.0-9]*)\u0020 (?P<request_creation_time>[^ ]*)\u0020 \"(?P<actions_executed>[^\"]*)\"\u0020 \"(?P<redirect_url>[^\"]*)\"\u0020 \"(?P<error_reason>[^\"]*)\"\u0020 \"(?P<target_port_ip>[^ ]*)[:-](?P<target_port_list>[0-9]*)\" """ RE_TEXT_PATH_LIST = [ 'list' ] RE_TEXT_JOIN_PATH = '|'.join(RE_TEXT_PATH_LIST) RE_FORMAT_ALB = re.compile(RE_TEXT_ALB, flags=re.VERBOSE) RE_FORMAT_PATH = re.compile(RE_TEXT_JOIN_PATH, re.IGNORECASE) s3_client = boto3.client('s3') logger = logging.getLogger() logger.setLevel(logging.INFO) def get_s3_object(s3bucket, s3key): response = s3_client.get_object(Bucket=s3bucket, Key=s3key) response_body = gzip.decompress( response['Body'].read()).decode('utf-8').splitlines() return response_body def parse_alb_log(log_datas): log_data_list = [] for log_data in log_datas: match = RE_FORMAT_ALB.match(log_data) if match: group_dict = match.groupdict() log_data_list.append(group_dict) return log_data_list def lambda_handler(event, context): try: s3bucket = event['Records'][0]['s3']['bucket']['name'] s3key = event['Records'][0]['s3']['object']['key'] s3_object = get_s3_object(s3bucket, s3key) alb_logs = parse_alb_log(s3_object) for alb_log in alb_logs: request_url = alb_log["request_url"] if RE_FORMAT_PATH.search(request_url): logger.info(json.dumps(alb_log)) else: pass except Exception as e: return logger.error("Failed to get object: {}".format(e)) |
「lambda_handler(event, context):」
の処理の流れですが、S3から取得したALBのアクセスログを「parse_alb_log()」でパースします。
|
1 |
alb_logs = parse_alb_log(s3_object) |
|
1 |
RE_FORMAT_PATH.search(request_url): |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
{ "type": "http", "time": "2020-01-28T09:13:45.350130Z", "elb": "app/test-web-alb/xxxxxxxxx", "client_ip": "xx.xx.xx.xx", "client_port": "58886", "target_ip": "xx.xx.xx.xx", "target_port": "80", "request_processing_time": "0.001", "target_processing_time": "0.001", "response_processing_time": "0.000", "elb_status_code": "200", "target_status_code": "200", "received_bytes": "478", "sent_bytes": "312", "request_method": "GET", "request_url": "http://example.com/list/index.html", "request_http_version": "HTTP/1.1", "user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36", "ssl_cipher": "-", "ssl_protocol": "-", "target_group_arn": "arn:aws:elasticloadbalancing:ap-northeast-1:xxxxxxx:targetgroup/test-web-tg/xxxxxxxx", "trace_id": "Root=1-5e2ffb49-b36867310f47acbc77cfe749", "domain_name": "-", "chosen_cert_arn": "-", "matched_rule_priority": "0", "request_creation_time": "2020-01-28T09:13:45.348000Z", "actions_executed": "forward", "redirect_url": "-", "error_reason": "-", "target_port_ip": "xx.x.xx.xx", "target_port_list": "80" } |
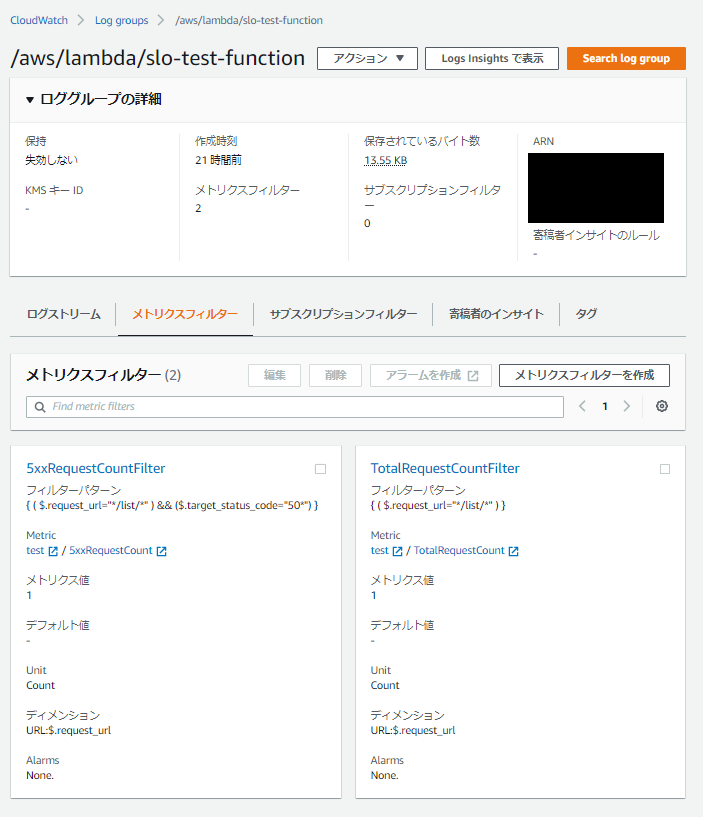
メトリクスフィルタの設定
メトリクスフィルタを利用してLambdaによって出力されたログから以下のメトリクスを作成していきます。- 5xxRequestCount
- 「http://example.com/list/index.html」に対しての50xリクエスト数
- TotalRequestCount
- 「http://example.com/list/index.html」に対しての総リクエスト数
|
1 |
{ ( $.request_url="*/list/*" ) && ($.target_status_code="50*") } |
|
1 |
{ ( $.request_url="*/list/*" ) } |
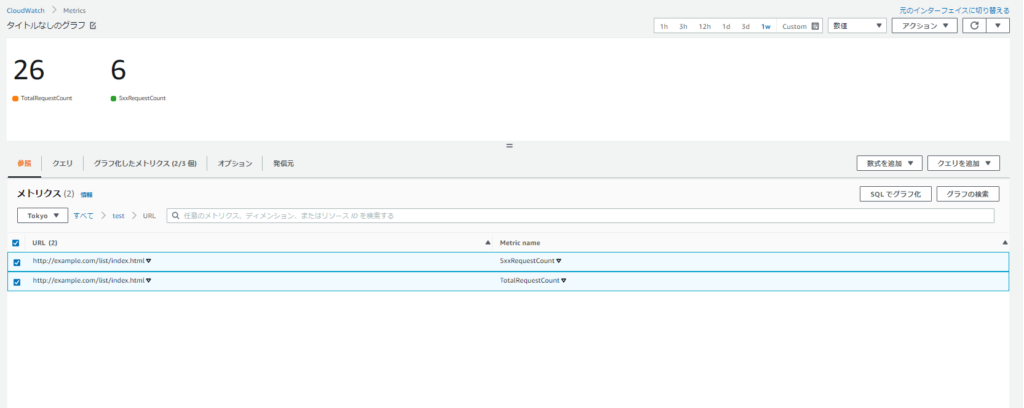
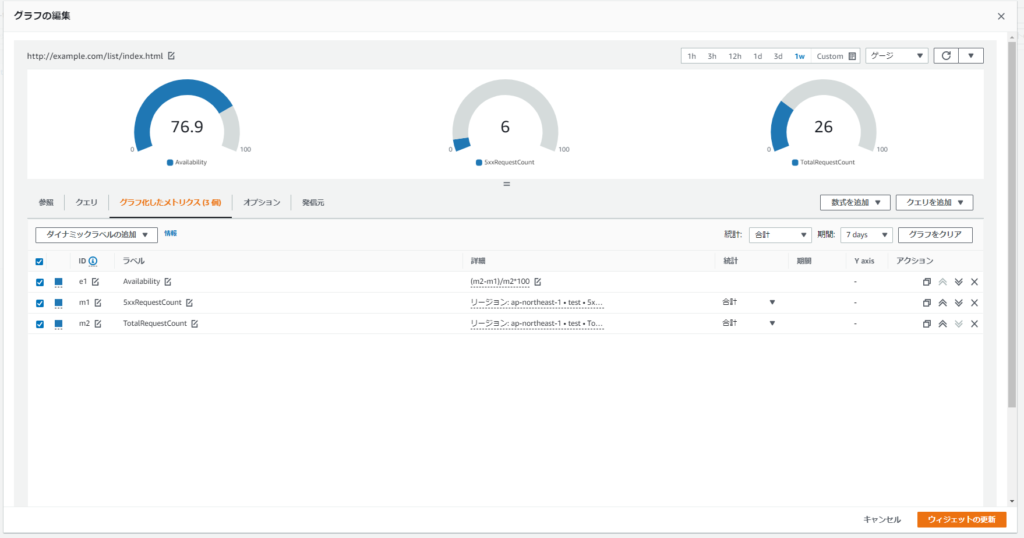
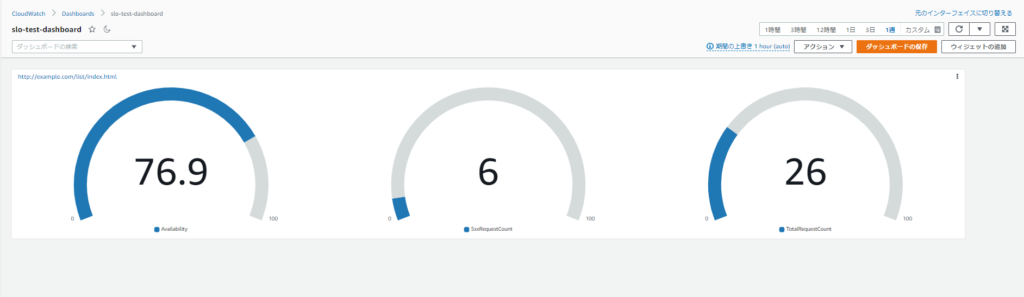
CloudWatchダッシュボードの設定
最後にメトリクスフィルタによって作成されたメトリクスをCloudWatchダッシュボード上に表示させるようにします。 ダッシュボードの作成方法についてはAWSの公式ドキュメントに書いてあるのでご参照ください。 作成した2つのメトリクスを利用して可用性 (総リクエスト数の内の50xリクエスト数以外の割合)を算出します。