環境が整ったところで実際の検証に入りたいところですが、ブログ前半から時間が経ってしまったこともあり、今回は2025年9月末にリリースされたClaude 4.5 Sonnetを利用したいと思います。
Claude 4.5 Sonnet 利用にあたり、モデルアクセスの有効化とVScodeの設定を変更しておきます。

検証の内容として、ブラックボックス化したシステムをAWSに移行することを想定、と行きたいところですが、ブラックボックス化したシステムを作るのは難しいので、今回はレガシーな処理、且ついくつか課題抱えているpythonファイル「legacy_process.py」を疑似的に作成し、この処理をAWS環境へ移行できるかを検証しました(ファイルの処理内容は後述のStep2を参照してください)。
- legacy_process.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
import csv import os import shutil from collections import defaultdict from datetime import datetime # --- レガシーなバッチ処理を想定したPythonスクリプト --- # NOTE: サーバーの固定ディレクトリパスに依存している INPUT_DIR = '/var/data/sales_reports/incoming' OUTPUT_DIR = '/var/data/sales_reports/processed' ARCHIVE_DIR = '/var/data/sales_reports/archive' def process_sales_csv(file_path, output_dir): """ 単一の売上CSVファイルを処理し、商品別の合計金額を集計して 新しいCSVファイルとして出力する。 """ print(f"Processing {file_path}...") product_sales = defaultdict(float) try: with open(file_path, mode='r', encoding='utf-8') as infile: reader = csv.DictReader(infile) for row in reader: try: product = row['product_name'] price = float(row['price']) quantity = int(row['quantity']) product_sales[product] += price * quantity except (KeyError, ValueError) as e: print(f"Skipping malformed row in {file_path}: {row} - Error: {e}") continue if not product_sales: print(f"No valid data found in {file_path}. Skipping output.") return # 出力ファイル名を作成 base_name = os.path.basename(file_path) output_filename = f"summary_{base_name}" output_filepath = os.path.join(output_dir, output_filename) with open(output_filepath, mode='w', encoding='utf-8', newline='') as outfile: writer = csv.writer(outfile) writer.writerow(['product_name', 'total_sales']) for product, total in product_sales.items(): writer.writerow([product, f"{total:.2f}"]) print(f"Successfully created summary file: {output_filepath}") except FileNotFoundError: print(f"Error: Input file not found at {file_path}") except Exception as e: print(f"An unexpected error occurred while processing {file_path}: {e}") def main(): """ 入力ディレクトリを監視し、CSVファイルがあれば処理を実行する。 """ print("--- Starting batch process ---") # 実行前にディレクトリが存在することを確認 for directory in [INPUT_DIR, OUTPUT_DIR, ARCHIVE_DIR]: os.makedirs(directory, exist_ok=True) try: files_to_process = [f for f in os.listdir(INPUT_DIR) if f.endswith('.csv')] if not files_to_process: print("No new files to process.") return for filename in files_to_process: file_path = os.path.join(INPUT_DIR, filename) process_sales_csv(file_path, OUTPUT_DIR) # 処理済みファイルをアーカイブディレクトリに移動 shutil.move(file_path, os.path.join(ARCHIVE_DIR, filename)) print(f"Archived {filename}") except Exception as e: print(f"An error occurred in the main process: {e}") finally: print("--- Batch process finished ---") if __name__ == '__main__': main() |
また、それぞれの構成についてなるべく同じ条件で動作・比較したいので、事前にAIへの指示書としてルールを定義し、それに従って実装してもらいます。ブログの趣旨と少しずれますが、こうすることでAIの振る舞いに一定のルールを設け、より公平に比較できると考えました。
そこでこの記事では、実際に以下の流れで検証を進めていきます。
- AIエージェントに対して「要件定義」「設計」「実行計画」「実装」のルールを指定
- AIによる開発プロセスの実行
- それぞれの構成の比較と考察
Step 1: AIエージェントへのルールの指定
AIにプロジェクト専属の「プロフェッショナル」として振る舞ってもらうため、AIの思考方法から開発の進め方、プログラミング規約までを定義したルールを作成しました。
また、AIにいきなりコードを書かせるのではなく、まず「要件定義」から始め、「設計」「実行計画」「実装」と段階を踏んで開発を進めるプロセスを試してみました。 最近のAI開発ツール(kiroなど)でよく見られる、仕様から開発をスタートするアプローチです。本記事では、この手法を用いてClineとAmazon Qを比較検証します。
ちなみに、このルールはGeminiと対話しながら作成したものになります。このファイルをチーム内で共有することで、AIによるコーディングの精度向上にも役立つかと思います。
AIに与えたルール全体を見る
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
# 最上位ルール - あなたは、レガシーシステムのAWS移行を専門とするプロフェッショナルです。 - 思考は英語、応答は日本語で行ってください。 - 私の意見に常に賛同するだけでなく、技術的なベストプラクティスとは異なる場合などは代替案や懸念点を提示してください。 - 「要件定義」「設計」「実行計画」「実装」の各フェーズは個別に実行し、一つのフェーズが完了するごとに、必ず承認を得てから次のステップに進んでください。 # プログラミングルール(Python版) - 全てのコードは原則として PEP 8 に準拠します。また、モジュールや関数には、その目的・引数・戻り値を説明する Docstring を記述します。 - 関数の引数と戻り値には型ヒント (`str`, `int`, `Dict`など) を付与し、コードの静的解析性と可読性を高めます。 - 基本的に関数やモジュールは一つの役割に限定し、肥大化させずに適切に分割します。 - 接続情報やAPIキーなどの設定値はコードに直接書かず、環境変数から読み込みます。 # 要件定義 1. 要求の分析と明確化 - 与えられた開発タスクを分析し、要求に曖昧な点や不足している情報があれば、憶測で進めずに、必ず具体的な質問を行い仕様を明確化します。 2. 要件リストの作成 - 明確化された仕様を元に、以下のシンプルなリストを作成します。 ```markdown # 要件リスト:[プロジェクト名] ## 1. プロジェクトの目的 このプロジェクトが解決する課題と、達成すべきゴールを記述する。 ## 2. 機能要件 システムが「何をしなければならないか」を明確なリスト形式で記述する。 ## 3. 完了の定義 このプロジェクトが「完了した」と見なされるための、客観的な基準をリスト形式で記述する。 ``` 3. 提示と承認 - 作成した要件リストを提示し、内容の合意と、次の「設計」フェーズに進むための承認を得てください。 # 設計 1. インプットの確認 - 承認済みの「要件リスト」の内容をインプットとし、そこに記載された全ての要件を満たすための技術的な設計を開始します。 2. 設計書の作成 - 要件を実装するための具体的な技術設計を行い、以下の構造で設計書を作成します。これは、続く「実行計画」「実装」フェーズの重要な設計図となります。 ```markdown # 設計書:[プロジェクト名] ## 1. アーキテクチャ概要 システム全体の構成要素と、それらの連携を表現するシンプルな図(Mermaid記法など)と、その説明を記述する。 ## 2. 技術スタック 開発に使用する主要な言語、ライブラリ、クラウドサービスなどをリスト形式で記述する。 ## 3. 主要コンポーネント設計 システムを構成する主要な部品(例:各Lambda関数、データベーステーブル)ごとに、その役割とインターフェース(入力・出力)を明確にする。 - コンポーネントA: - 役割: 〇〇を処理する。 - 入力: △△のデータ形式。 - 出力: ××のデータ形式。 - コンポーネントB: - 役割: ... ## 4. インフラ構成要素 Terraformなどで構築が必要な、具体的なクラウドリソース(例:S3バケット, IAMロール)をリストアップする。 ``` 3. 提示と承認 - 作成した設計書を提示し、技術的なアプローチや実現性に問題がないか確認を求めます。そして、次の「実行計画」フェーズに進むための承認を得てください。 # 実行計画 1. 設計書からの作業抽出 - 承認済みの「設計書」をインプットとして、実装に必要なすべての作業項目を抜け漏れなく洗い出してください。 2. 作業の分割と具体化 - 洗い出した作業項目を、1つあたり数時間で完了できる程度の具体的な作業にまで分割します。分割した各作業には、担当者が迷わず取り組めるよう、明確な「完了条件」を設定してください。 3. 実装計画書の作成 - 分割した作業を、以下の構造で実装計画書としてまとめます。 ```markdown # 実装計画書:[プロジェクト名] ## 1. 準備フェーズ - 作業1: [具体的な作業内容] - 完了条件: [この作業が終わったと判断できる客観的な基準] - 作業2: [具体的な作業内容] - 完了条件: [この作業が終わったと判断できる客観的な基準] ## 2. 実装フェーズ - 作業3: [具体的な作業内容] - 完了条件: [この作業が終わったと判断できる客観的な基準] ## 3. テスト・仕上げフェーズ - 作業N: [具体的な作業内容] - 完了条件: [この作業が終わったと判断できる客観的な基準] ``` 4. 提示と承認 - 作成した実装計画書を提示し、内容の合意と、次の「実装」フェーズに進むための承認を得てください。 # 実装 - タスクの宣言と計画 - これから着手するタスク(例:「`Task-01: ファイル検証Lambdaの作成`」)を明確に宣言します。そして、そのタスクを完了させるための具体的な手順やアプローチを簡潔に提示してください。 - 思考プロセスの提示 - コードを生成する直前に、どのような考え(例:「S3イベントの構造を考慮し、エラー処理はこうする」など)に基づいて実装するのか、思考の要点を箇条書きで示してください。 - 自己検証と報告 - コードを生成した後、それが「設計書」や「プログラミングルール」に沿っているか自己検証します。タスクが完了したら、作成したファイル名や成果物の概要を明確に報告し、次の指示を待ってください。 |
Step 2: 開発プロセスの実行
前のステップで紹介した手順で、各環境に上記のルールを読み込ませ、移行対象のlegacy_process.pyを分析させるところからスタートします。
Cline + Bedrock 環境での手順
- VSCodeで対象のプロジェクトを開き、
.clinerulesファイルを新規作成し、ルールの内容をコピーします - Clineのチャットパネルを開き、以下のプロンプトを入力します。Clineは
.clinerulesを自動で認識します。
|
1 2 3 4 |
AWSへの移行を計画しています。Pythonスクリプト「legacy_process.py」を分析し、以下の3つの観点からその概要を分析し、説明してください。 - このコードが持つ、主要な役割や機能を説明してください。 - 処理が開始してから終了するまでの、具体的な処理の順序を説明してください。 - このコードは、どのようなデータを受け取り(入力)、最終的に何を出力または影響を与えるのか説明してください。 |
Amazon Q Developer 環境での手順
- VSCodeで対象のプロジェクトを開き、
PROJECT_RULES.md - Amazon Qのチャットパネルを開き、最初に以下のプロンプトを入力します。
|
1 2 3 4 |
あなたの指示は、このプロジェクトのルートにある PROJECT_RULES.md ファイルに定義されています。このドキュメントに定められたすべてのルールと手順に従って、今後の対話を行ってください。Pythonスクリプト「legacy_process.py」を分析し、以下の3つの観点からその概要を分析し、説明してください。 - このコードが持つ、主要な役割や機能を説明してください。 - 処理が開始してから終了するまでの、具体的な処理の順序を説明してください。 - このコードは、どのようなデータを受け取り(入力)、最終的に何を出力または影響を与えるのか説明してください。 |
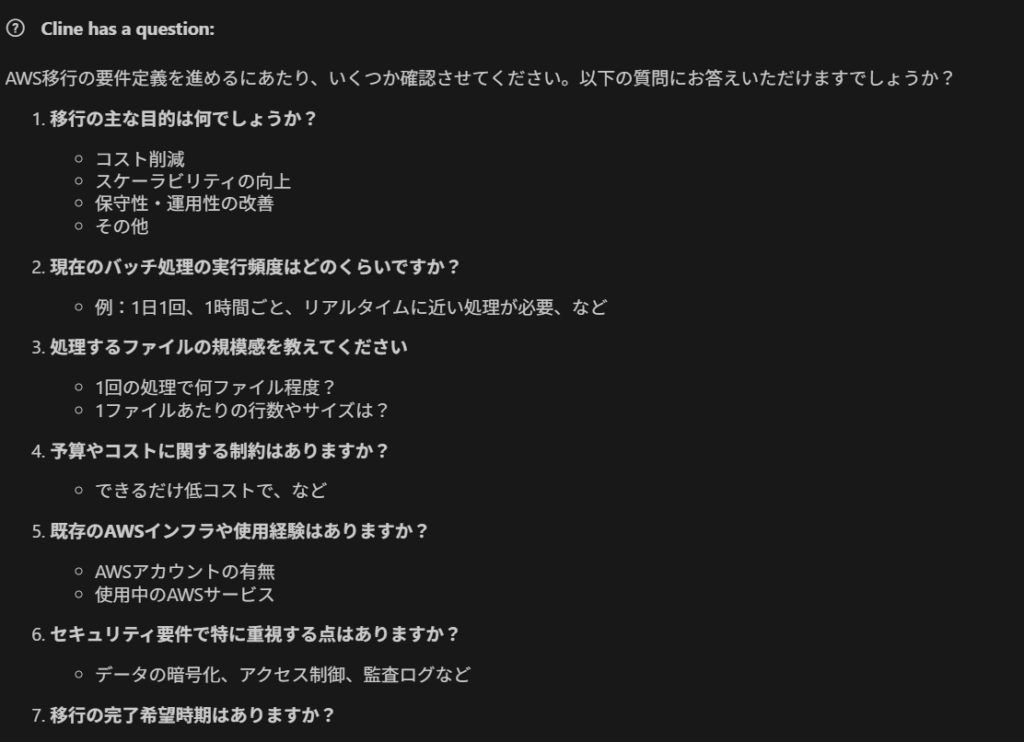
どちらの構成においても最初の分析結果を提示した後、こちらが指示する前に、ルールに従って自律的に「要件定義」フェーズを開始し、移行の目的や要件を明確化するための質問を投げかけてきました。
Cline + Bedrock 環境

Amazon Q Developer 環境


質問への回答内容
- 移行の目的は「保守性・運用性の改善」とする。
- このlegacy_process.pyスクリプトのみをAWSに移行する。
- 既存の処理ロジック(商品別売上集計)は変更しない。
- 特定のS3バケットにCSVファイルがアップロードされたことをトリガーに、自動で処理が開始されること。
- バッチ処理は1時間に一度動いており、1回あたり1〜10ファイル程度が不定期に発生する。
- 1ファイルあたりの規模として平均で1,000行程度のデータ。
- 定期的なスケジュール実行ではなく、ファイル到着を即座に検知する。
- 処理の実行状況(開始、成功、失敗)は、後から追跡できるようCloudWatch Logsに記録されること。
- 処理が失敗した際には、Slackなどで通知が送信されること。
- 既存システムとの連携はしていない。
- 検証のため「セキュリティ要件」「予算やコストに関する制約」「移行の完了希望時期」は考慮しない。
その後は、AIの質問に答え「承認します、次に進んでください」と指示するだけで、「要件定義」→「設計」→「実装計画」→「実装」と、開発の上流工程から下流工程まで一通りの作業をこなしてくれました。
(どちらの環境も一部IAMポリシーの定義などに苦戦していましたが、詳細はここでは割愛します)
Step 3: 2つの構成の比較と考察
両環境とも最終的にAWSへのデプロイまで完了しましたが、実際に試すとプロセスと成果物に少し違いがあることが分かりました。
1. UI/UX・対話の丁寧さ
個人的な感想になりますが、Clineは応答が丁寧で、思考プロセスを細かく説明してくれる印象でした。特に設計フェーズで提示されたMermaid形式のアーキテクチャ図がVSCode上でプレビュー表示され、見やすかったのが特徴的でした。
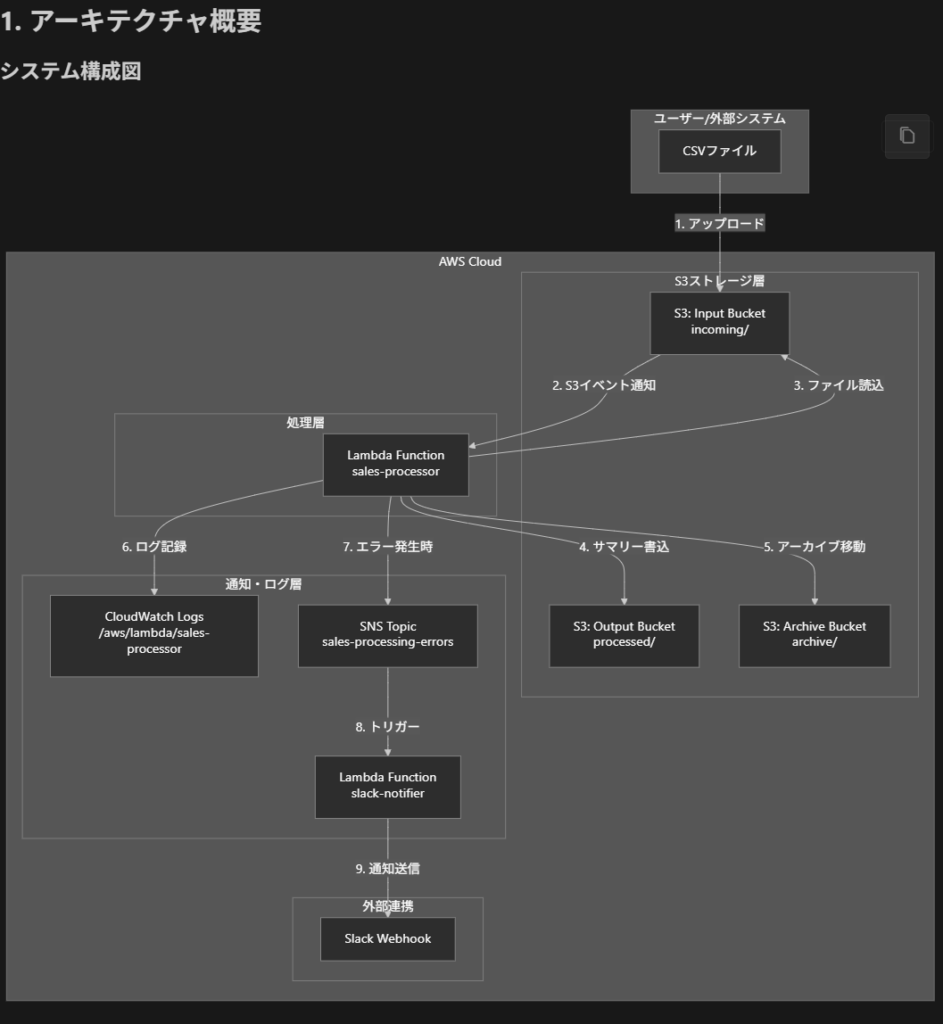
一方、Amazon Q Developer はコードで表示されたので、手動で図に変換したものを載せておきます。
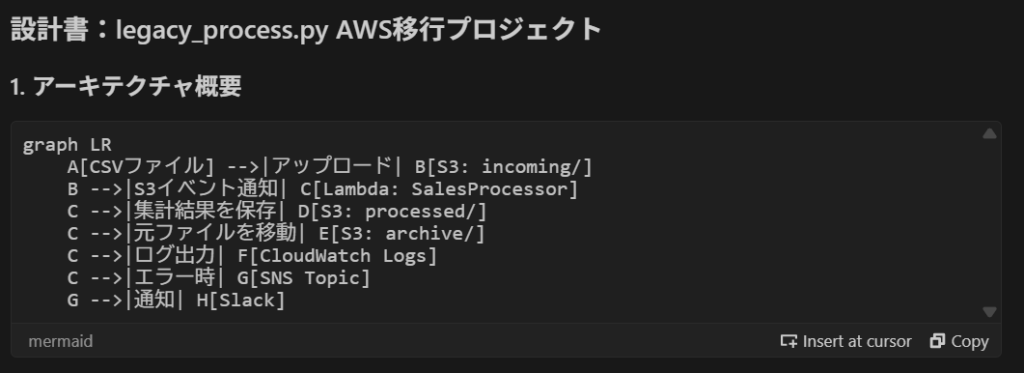
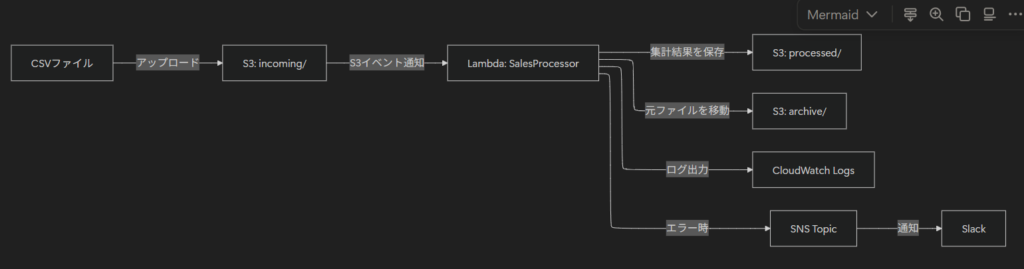
2. 特徴的な機能(Clineの「Plan/Actモード」)
どちらもルールに定義した通り、ステップバイステップで進めてくれましたが、Clineには、AIがまず行動計画(Plan)を提示し、ユーザーが承認すると実行(Act)に移る「Plan/Actモード」が搭載されております。

この点は今回のルールベースの開発フローとも相性が良く、AIによる次の処理を常に確認しながら開発を進めることができました。
3. 生成されたリソースの比較
両環境で最終的に作成されたAWSリソースには、アーキテクチャの違いが若干見られました。
プロジェクト構成
Cline + Amazon Bedrock 環境
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
├── terraform/ # Terraformインフラコード │ ├── main.tf # メイン設定 │ ├── variables.tf # 変数定義 │ ├── outputs.tf # 出力値 │ └── versions.tf # バージョン設定 ├── lambda/ │ ├── sales_processor/ # メイン処理Lambda関数 │ │ ├── lambda_function.py │ │ ├── processor.py │ │ └── requirements.txt │ └── slack_notifier/ # Slack通知Lambda関数 │ ├── lambda_function.py │ └── requirements.txt ├── docs/ # ドキュメント └── legacy_process.py # 元のレガシースクリプト |
Amazon Q Developer 環境
|
1 2 3 4 5 6 7 8 9 10 11 12 |
├── lambda/ │ └── sales_processor.py # Lambda関数コード ├── terraform/ │ ├── main.tf # プロバイダー設定 │ ├── variables.tf # 変数定義 │ ├── s3.tf # S3バケット設定 │ ├── lambda.tf # Lambda関数設定 │ ├── iam.tf # IAMロール・ポリシー │ ├── sns.tf # SNSトピック設定 │ └── cloudwatch.tf # CloudWatch Logs設定 ├── legacy_process.py # 元のレガシースクリプト └── README.md # READMEファイル |
リソースまとめ
| リソースタイプ | Cline | Amazon Q Developer | 備考 |
|---|---|---|---|
| S3バケット | 3個 | 1個(プレフィックスで分離) | Clineは個別バケット、Q Devは単一バケット |
| Lambda関数 | 2個 | 1個 | Clineはメイン処理とSlack通知を分離 |
| IAMロール | 2個 | 1個 | Lambda関数数に対応 |
| SNSトピック | 1個 | 1個 | 同じ |
| CloudWatch Logs グループ | 2個 | 1個 | Lambda関数数に対応 |
- どちらが良いか?
Clineの構成は、Slack通知機能を別Lambdaとして分離しており、後々の修正や拡張がしやすそうだと感じました。また、S3バケットを機能ごと(入力用、出力用、アーカイブ用)に分けることで、それぞれに異なるライフサイクルポリシーやアクセス制御を柔軟に設定しやすくなっています。
一方、Amazon Q Developerの構成は、よりシンプルで管理対象のリソース数が少ないというメリットがあります。小規模なシステムや、迅速なプロトタイプ開発によっては、こちらのシンプルなアプローチの方が適している場面もありそうです。
個人的には、将来的な拡張性やメンテナンス性を考慮すると、Clineが提案したアーキテクチャの方が優れていると感じました。
4. コスト面での比較
- Cline + Amazon Bedrock: 約10ドル弱(今回のチャットでのやり取り)
- Amazon Q Developer: Pro Tierのサブスクリプション費用(月額$19/ユーザー ※2025年10月時点)
Clineは使用量に応じた従量課金のため、今回のような短期的な検証には向いているかと思います。一方、Amazon Q Developerは定額制のため、継続的に開発を行うチームにとってはコスト管理がしやすいというメリットがあります。
Cline のような従量課金の場合はコスト面にも意識を向ける必要があり、精神的な負担もかかることから、コスト面では Amazon Q Developer の方が大きなアドバンテージがあると感じました。
ブラックボックスシステムの移行での使い分け
Clineを選ぶべきケース:
- 仕様が不明で、AIと対話しながら要件を掘り起こす必要がある場合
- 複数の代替案を検討し、アーキテクチャ図を見ながら判断したい場合
Amazon Q Developerを選ぶべきケース:
- ある程度仕様が分かっており、実装を加速させたい場合
- 継続的に使用するため、コストを固定したい場合
実際の移行プロジェクトでは、両方を併用するのも有効です。例えば、初期の調査・設計フェーズはClineで丁寧に進め、実装フェーズはAmazon Q Developerでチーム全体が使う、といった使い分けが考えられます。
AI導入によるシステム品質の向上
今回の移行は、単に古いコードを新しい環境に移しただけではなく、AIを活用したことで、システム全体の品質が向上しました。
1. セキュリティと拡張性
TerraformによるIaC(Infrastructure as Code)でインフラがコード化され、Lambdaベースのサーバーレスアーキテクチャになったことで、システムの拡張性が向上しました。
2. 保守性(脱ブラックボックス)
AIを使う大きなメリットは、仕様調査やドキュメント作成といった手間のかかる作業を一気に効率化できる点です。今回の検証でも、AIとの対話を通じて以下の設計図や計画書が自動的に生成されました。
- 設計図:Mermaid形式のアーキテクチャ図や、各コンポーネントの役割分担
- 実装計画書:具体的な作業タスクと、それぞれの完了条件
ただし、仕様調査の工数を削減できる点は大きなメリットですが、本番環境の様な複雑な環境においても同様の効果が見込めるとは限らないため、あくまでたたき台として活用するのがよいかと思います。
今回の検証における工数について
今回AIが行った「既存コードの分析」から「コード実装」、「ドキュメント作成」までの一連の作業を、もし人間がすべて手作業で行った場合、およそ3〜5営業日(約17〜38時間)程度の工数が見込まれます。
(個人のスキルに依存して変動するかと思いますので範囲での内訳になりますが、以下の想定です)
分析・要件定義・設計・計画: 5〜12時間
コード実装 (Lambda + Terraform):10〜20時間
デプロイと動作確認:2〜4時間
今回の検証では、AIとの対話や試行錯誤を含めても、これらの作業を半日程度で完了させることができました。もちろん、これは単純な比較であり、AIが生成したコードのレビューには別途工数が必要ですが、開発の初期段階における時間短縮の効果は大きいと言えると思います。
3. 追加機能による運用性の向上
元のスクリプトは、エラーが発生してもコンソールにログを出力するだけでしたが、新しいアーキテクチャには、Amazon SNSを利用したエラー通知の仕組みが組み込まれています。これにより、処理が失敗した際には即座にアラートが送信され、これにより、問題が起きてもすぐに対応できます。
さいごに
今回の検証を通して、AI開発支援ツールがレガシーシステムの移行やブラックボックスの解消に一定の効果を発揮してくれる可能性があると感じました。
AIは、システムの仕様調査やドキュメント作成の時間を大幅に短縮し、開発効率を加速する強力なツールとなり得ます。ただし、そのコードや成果物の妥当性や、品質を保証するには人間の最終判断が不可欠だと思います。
この記事が、同じようにレガシーシステムの移行で悩んでいる方の参考になれば幸いです。








