この記事は、ニフティグループ Advent Calendar 2022 5日目の記事です。
はじめに
会員システムグループ SREチームの浅見(@rubihiko)です。
インシデント管理、リスク分析の重要性の高まりから色々調べていたところ、以下の記事の記事をみて良いと思ったので試してみました。
Googleでは 稼働準備レビュー(PRR) 時に リスクを優先順位付けして明確化 することを推奨しているようで、ニフティでもProduction Readiness Checklistを作って運用し始めているので、取り入れていきたいなと思っています。
用語の説明
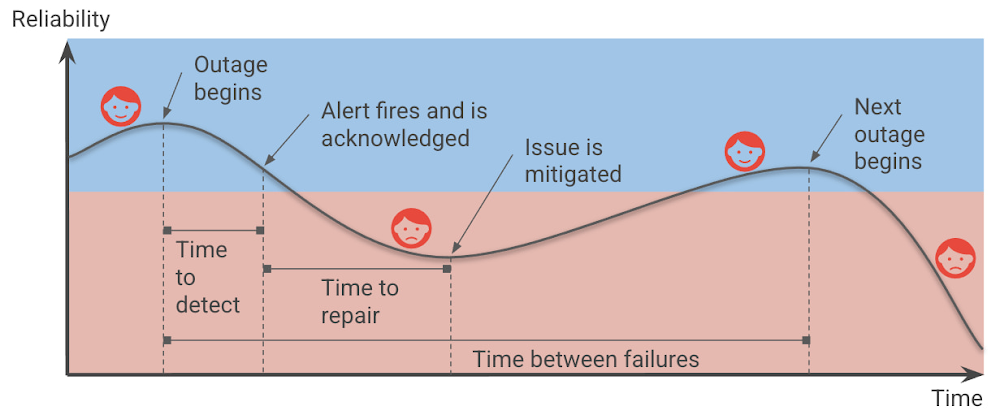
平均検出時間(MTTD:Mean Time To Detect)
問題が発生し、修復する人(やシステム)が検知するまでの平均時間です平均修復時間(MTTR:Mean Time To Repair)
人(やシステム)が問題を検知して、それを修復するためにかかった平均時間です平均障害間隔(MTBF:Mean Time Between Failures)
障害を復旧させサービスが使えるようになってから、次の障害が発生するまでの平均時間ですMTTD と MTTR と MTBFの関係
年間の損失
以下の数式でリスクに対しての年間の損失が導けます(MTTD + MTTR) * (365.25 / MTBF) * percent of affected users
|
1 2 3 4 5 |
MTTD(分): 5分 MTTR(分): 120分 MTBF(日): 365日 (5 + 120) * (365.25 / 365) * 100% = 125分 |
リスク分析
MTTD, MTTR, MTBFの関係がわかりました。 これにユーザーインパクトを加えると損失を導くことができました。 この計算式を使い、リスク分析へと進んでいきます。 今回は、サンプル事例とデータを使って見ていきたいと思います。 記事の中に、リスク分析のためのテンプレートがあるためこちらをコピーして使います。 このテンプレートはいくつかのシートで構成されており、リスクの洗い出し、要素の洗い出し、リスク許容の判断をすることが出来ます。 ※ ここでは、テンプレートに書いてある用語を以下のよう置き換えて考えています- ETTD = MTTD
- ETTR = MTTR
- ETTF = MTBF
ETTD Estimated Time To Detection – how long it would take to detect and notify a human (or robot) that the risk has occurred; aka MTTD.
ETTR Estimated Time To Resolution – how long it would take to fix the incident once the human (or robot) has been notified; aka MTTR.
ETTF Estimated Time To Failure – estimated frequency between instances of this risk; aka MTBF.
リスクカタログ
リスクの洗い出しを行います。 過去にあった障害をベースに考えるのがよいと思います。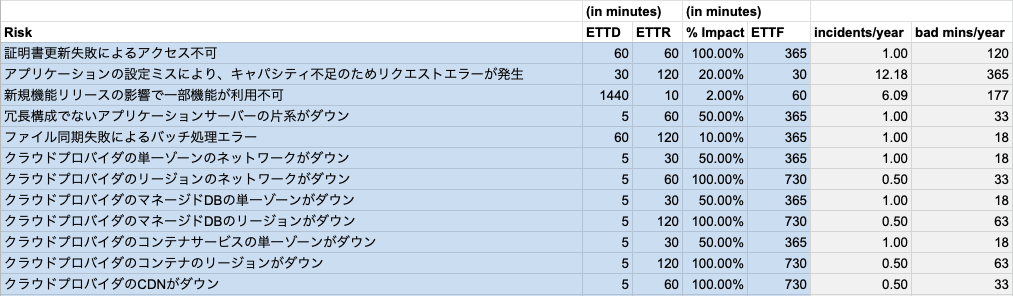
このリスクカタログにある、
「新規機能リリースの影響で一部機能が利用不可」 の項目の場合の詳細としては、「リリースをしたが、ある一定数のユーザーに対してエラーとなっており、それに気がついたのは1日後だった。気がついた後10分で切り戻しを行い解消した。この障害は60日毎に発生してた。」としたものです。
つまり表に入力する値としては以下のようになります。
- 一定数のユーザーに対してエラー:
impact 2% - 気がついたのは1日後:
MTTD 1440(min) - 気がついた後10分で切り戻しを行い解消:
MTTR 10(min) - この障害は60日毎に発生してた:
MTBF 60(days)
- 年間の平均障害数:
incidents/year 6.09(回) - 年間の平均障害時間:
bad mins/year 177(min)
リスクファクター
リスク全体に影響を及ぼすような要素を洗い出します リスクカタログで挙げたリストに対して、影響を与える要素を追加することになります。 追加する観点は、MTTD, MTTR, MTBFどれを使っても構いません。
例えば、
「運用過負荷のため、障害検知時間(MTTD)がインシデント毎に+30分増加」 などは、通常の業務が忙しすぎたりしてアラートに気が付かない、他に優先度が高いタスクがありアラートを受け取れない、などが課題としてあり、全てのリスクに対して、MTTRが+30分増加するというものです。
また、「運用手順書が不足しているため、障害復旧時間(MTTR)がインシデント毎に+10分増加」 はアラートに気が付き対処を開始したが、復旧のための運用手順書が不足しているので、通常よりMTTRが+10分増加してしまうというものです。
このように、全ての障害に影響を与える要素について、リスク(bad mins/year)として追加しているわけです。
リスクスタックランク
これまで洗い出したリスクのカタログ・要素を並び替えます このテンプレートを使えば以下のよう自動で並び替えをしてくれます。 ここからは、SLOに対して、どの程度リスクを許容できるか確認するフェーズになります。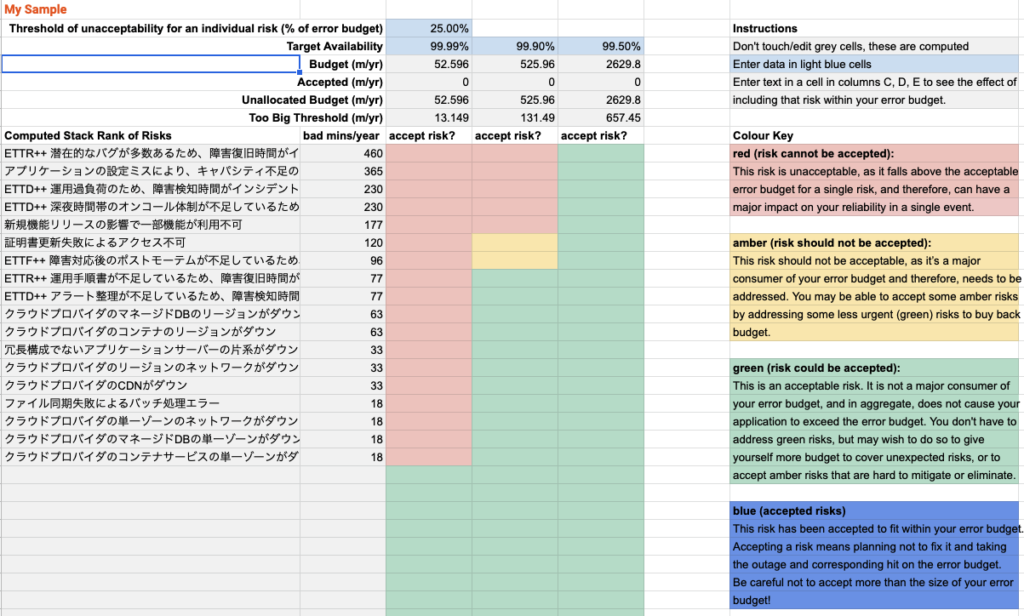
SLO 99.5% なら全てのリスクを許容してもエラー予算は余りますが・・・
SLO 99.5%の可用性は、年間43.8時間の停止を許容する目標となりますが、ユーザーに見せているサービスとしては低いので良くないように思えます。 社内で利用しているツールや実験的なサービスならありかもしれません。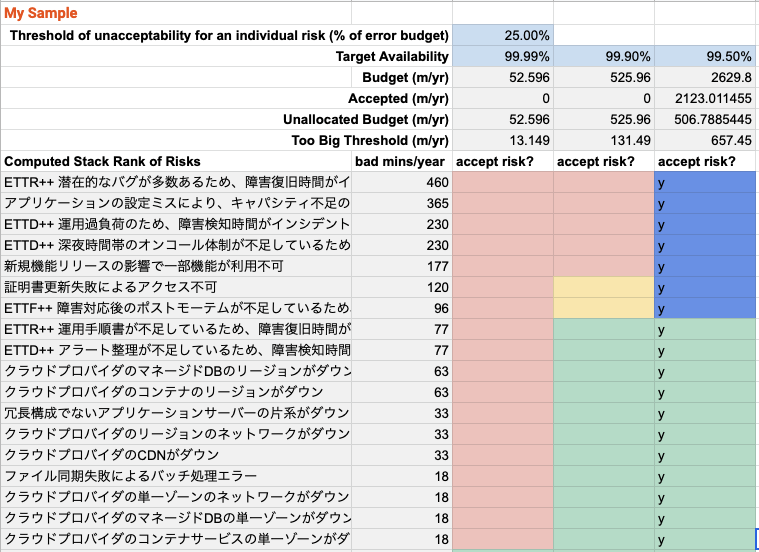
99.9%, 99.99% を求める場合は当然許容できるリスクが減ります
SLO 99.9%, 99.99%の場合はどうなるか見てみます。 SLOが厳しくなるほど許容できるリスクが少なくなっているのが下の図から分かると思います。 リスクを許容しすぎるとエラー予算がなくなってしまい、SLOを維持できなくなってしまいます。 これは、ユーザーへの信頼性低下へと繋がります。 ここでは、下から適当にリスク許容としていますが、実際にはSLOに基づいた適切なリスク許容をする必要があります。 このようにリスクを数値化したことで、データドリブンのアプローチが可能になったのはすごいことだと思います。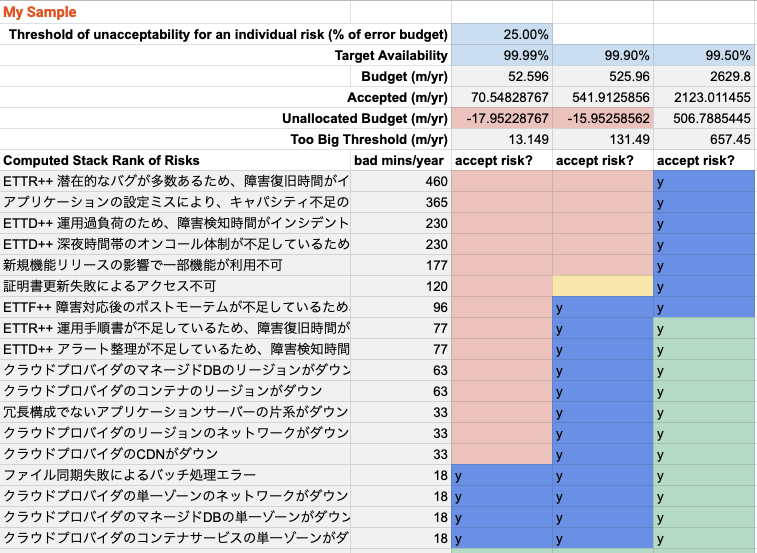
リスクの許容
分析したリスクは、プロダクト開発にも影響する大きい要素です。 ビジネスサイド(PO)とエンジニアサイドで議論して決める必要があります。 リスクを許容した上で施策を進めるのか、それとも時間をとって改善するのか。 このようなデータがあることでプロジェクトの進行判断の材料になります。まとめ
リスクを数値化したことで潜在的なリスクを明るみにして、優先度付けできました。 テンプレが整っているので、Production Readiness Checklistにも容易に組み込めるのでとても良い考えだと思います。- リスクを可視化するには MTTD, MTTR, MTBF, ユーザーインパクトを使う
- MTTD: アラートが上がってから検知するまでの平均時間
- MTTR: アラートを受け取ってから対応を完了するまでの平均時間
- MTBF: サービスが正常になった点から次に障害発生するまでの平均時間
- MTTD, MTTR をできるだけ短くすることが信頼性向上につながる
- MTBF をできるだけ長い期間にすることは信頼性向上につながる
- リスクを分析すること
- リスクやリスクを増加させる要素を洗い出し、数値化し、分析する
- リスクを評価し許容を検討する
- ユーザーインパクト、ビジネスインパクト、現実的な問題など話し合って決める
- SLOに応じてリスクは許容できることを理解する
- SLO 99.99%: ほぼ許容出来ない
- SLO 99.90%: 一部許容できる
- SLO 99.50%: ほとんど許容できる
明日は、supreme3854さんのtkinterで残業代計算です。
お楽しみに!








