はじめに
会員システムグループのkiqkiqです。最近PySparkというライブラリを触ってみたので紹介したいと思います。
Apache Spark・PySparkとは
PySparkは、Pythonを使ってApache Sparkを操作するためのライブラリです。そのApache Sparkというのは、オープンソースの大規模データ処理フレームワークで、高速で汎用的なデータ処理エンジンです。Sparkには主に4つの特徴があります。
- 分散処理 Sparkはクラスター上で分散処理を行うことができ、大量のデータを効率的に処理することができる
- 高速 メモリ内で処理を行い、複数の並列操作でジョブのステップ数を減らすことでデータを再利用することができる
- 汎用性 Sparkはバッチ処理だけではなく、ストリーミング処理、機械学習、グラフ処理などのデータ処理に対応
- 多様なAPI Sparkは、Scala、Java、Python、R など、さまざまなプログラミング言語からアクセスできる
これらの特徴から、Spark関連のものは大規模データ処理、機械学習、ストリーミング処理など、さまざまな用途で利用されています。このブログではPySparkの基本的な機能や簡単な使い方などを紹介していきます。
機能紹介
- Spark SQL
- Spark SQL は、SQLライクなクエリ言語を使ってデータ処理ができる。 SQLを使ったデータ分析や 抽出、変換、ロードのようなタスクを簡単に実行できるもの。
- Spark Streaming
- Spark Streamingは、リアルタイムのデータストリーミング処理を可能にするコンポーネント。Spark Streamingでは数秒ほどの短い間隔に区切られたバッチ処理を繰り返し行い、ストリームデータ処理機能を実現されている。
- MLlib
- MLlibは、Sparkに組み込まれている機械学習のライブラリで、分類、回帰、クラスタリング、共起分析などの主要な機械学習アルゴリズムが用意されている。
- GraphX
- GraphXは、グラフ処理のための Spark のコンポーネントで、ソーシャルネットワーク分析、推薦システム、ルーティングアルゴリズムなど、グラフ構造のデータを扱うことに特化した機能。また、組み込まれているグラフ処理用の API を使って、グラフの作成、変換、分析などの処理を行える。
使い方
環境構築
今回はjupyter notebookとpysparkがインストールされたコンテナイメージjupyter/pyspark-notebook上で実行していきます。以下のdocker-compose.ymlを実行するだけでpysparkを実行できる環境を構築できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
version: '3' services: jupyter: image: jupyter/pyspark-notebook ports: - "8888:8888" # notebook のポート - "4090:4040" # Spark UI のポート environment: - JUPYTER_ENABLE_LAB=yes - CHOWN_HOME=yes - CHOWN_HOME_OPTS=-R - GRANT_SUDO=yes - NB_UID=1000 - NB_GID=100 command: start-notebook.sh --NotebookApp.token='' |
また、この記事では気象庁が公開している神戸市の気象データを使用します。https://www.data.jma.go.jp/gmd/risk/obsdl/
実行
PySparkのDataFrameを使用しSpark SQLの使い方を紹介します。
SparkSessionの作成とPySparkのDataFrameへの変換は以下のように行います (また、SparkSessionの作成時にワーカーノード上のExecutorの設定もできる)
|
1 2 3 |
from pyspark.sql import SparkSession spark = SparkSession.builder.appName("spack test").getOrCreate() |
PySparkのDataFrameはpandasと同じような操作ができます
|
1 |
df = spark.read.format("csv").option("inferSchema","True").option('encoding', 'shift_jis').option("sep",",").option("header","True").load("../data/data.csv") |
PySparkのDataFrameに対してSpark SQLを用いてSQLの操作を行うことができます (普通のselect3件)
|
1 |
spark.sql("select * from data limit 3").show() |
|
1 2 3 4 5 6 7 |
+---------+--------+---------+---------+--------+---------+---------------+---------+---------+----+----------+---------------+----------+----------+ | 日時|最低気温|品質情報2|均質番号3|最高気温|品質情報5| _c6|品質情報7|均質番号8| _c9|品質情報10| _c11|品質情報12|均質番号13| +---------+--------+---------+---------+--------+---------+---------------+---------+---------+----+----------+---------------+----------+----------+ |2020/6/20| 22.7| 8| 1| 26.5| 8|2020/6/20 14:20| 8| 1|20.0| 8|2020/6/20 05:19| 8| 1| |2020/6/21| 23.7| 8| 1| 28.2| 8|2020/6/21 15:03| 8| 1|18.5| 8|2020/6/21 04:39| 8| 1| |2020/6/22| 25.8| 8| 1| 29.2| 8|2020/6/22 15:57| 8| 1|23.2| 8|2020/6/22 05:53| 8| 1| +---------+--------+---------+---------+--------+---------+---------------+---------+---------+----+----------+---------------+----------+----------+ |
このように普通のSQLの実行結果のように出力することができます。
結果の確認
Spark UIの「SQL / DataFrame」タブで実行情報を確認できます
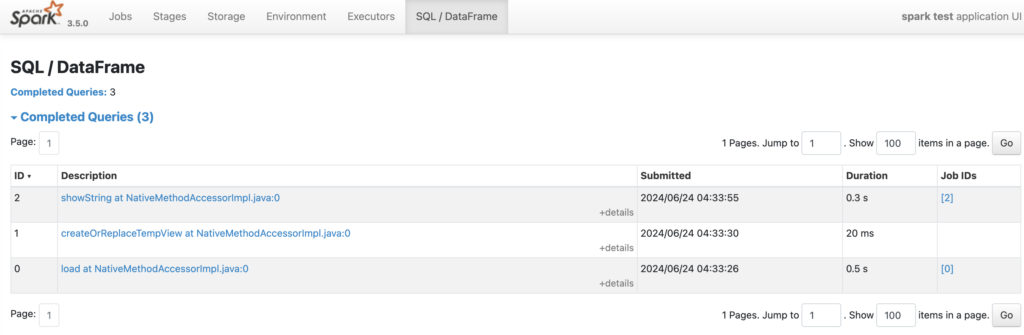
また、SparkSession作成時に設定したExecutor(ワーカーノード上で実行されるプロセス)などの確認はEnvironmentタブやExecutorsタブで確認することができます。
ブログ内で使用した程度のデータの規模だとSparkを使用する意味はほとんどありませんが、大きいデータになれば分散処理による工夫が必要ななるため、Sparkなどが有効になると思います。
おわりに
PySparkを使用すればPandasやSQLを使うように簡単に分散処理を実行することができるので、分散処理に興味がある方や大規模なデータ分析をする方は試してみてください。