インフラシステム所属 新卒3年目エンジニアです。
業務ではPHP、趣味ではC++、Pythonを書いているコーディングジャンキーです。
道端でふとコーディングをしたくなることってありますよね。
本稿では業務でも趣味でも使っているWebブラウザ自動操作フレームワークのSeleniumについて紹介したいと思います。
Seleniumはプログラムによる自動操作という特性上、サービスを提供する側から見ると、
想定以上の負荷がかかります。
なので、サービス毎のルールを基に用法・用量を守ってお使いください。
本稿ではSeleniumの基本的な使い方について紹介します。
Seleniumとは?
Seleniumとは、人間の代わりにプログラムがブラウザを自動操作するフレームワークです。
主な用途としては、情報収集から開発中のWebアプリケーションのテストまで、
人力よりは素早く時短が出来るのが強みです。
Webアプリケーションを開発した際に、動作を確認することはもはや必須です。
しかし、アプリケーションの規模が大きければ大きい程、確認作業も比例して大変になります。
そこで、手動で操作していた確認作業を自動化したいという願いを叶えるのが、このSeleniumとなります。
例えば、情報を検索し閲覧するアプリがあったとします。
そのアプリで複数のユーザーの情報を確認する場合、本来ならば全員分のユーザーIDを入力して目視で確認する必要があります。
Seleniumを使えばユーザーID一覧ファイルでまとめて読み込ませ、確認したい情報はデータとして出力させることが出来ます。
あとはその一括に纏められたデータを確認することで、比較的高速で終わらせることが出来ます。
テキストだけでなく、ページ全体の状態を確認したいときにはスクリーンショットを取る事も出来ます。
自動ブラウジング体験
本稿ではサンプルを用いて Selenium を使った自動ブラウジングの基本を提示いたします。
自動テストやスクレイピングのなどに応用する為の足掛かりになれば幸いです。
サンプルではブラウザを起動し、Google検索を行いスクリーンショットを取るということを自動で行います。
普段は手動で行っている一連の動作を自動化する所から、是非時短技術を身に着けていってください!
利用準備
- Windows環境を想定しています
- Python 3.7以降
- ブラウザドライバー (利用中のブラウザとバージョンが最も近い物)
- Python Selenium ライブラリ
- pip にてインストールする場合は以下のコマンドをコマンドプロンプト等で実行します
|
1 |
pip install selenium |
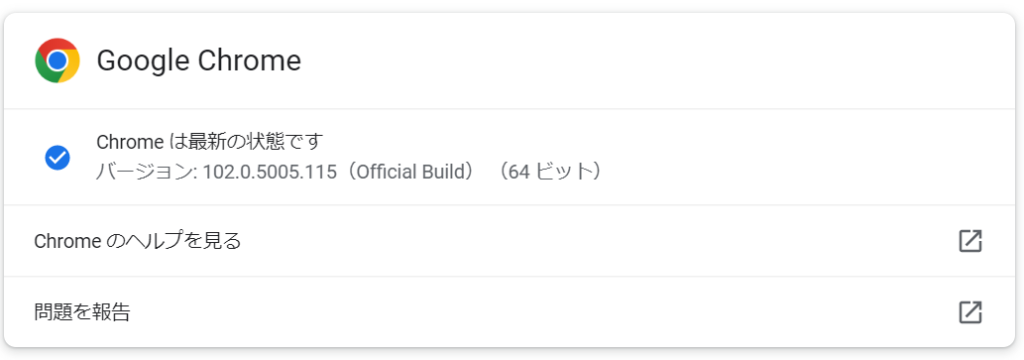
ブラウザのバージョンの確認方法としまして、
Google Chromeならば、ツールバーのメニューから[ヘルプ]→[Google Chromeについて]から。
Microsoft Edgeならば、ツールバーのメニューから[ヘルプとフィードバック]→[Microsoft Edgeについて]にて確認することが出来ます。
バージョン等は一例として以下に挙げますが、ドライバーのバージョンと完全に一致しない場合もあります。
ブラウザのバージョン 102.0.5005.115 に対し、ダウンロード可能なドライバーは 102.0.5005.61 ですが、末尾について多少差異があっても動作します。
(バージョンは執筆当時 2022/06/22 の状態となります。)
ファイル構成
|
1 2 3 4 5 6 |
selenium_sample/ - drivers/ # ダウンロードしたドライバーを入れるディレクトリ - msedgedriver.exe # Microsoft Edge ドライバー - chromedriver.exe # Google Chrome ドライバー - sample_basic.py # 動作デモ - search_result.png # デモ動作後に出力されるスクリーンショット |
動作デモ(sample_basic.py)
- 当デモスクリプトは、以下の動作を行います
- 1. 前提となるブラウザを起動し、インストール等が正常かを確認します
- 2. Google検索へアクセスします
- 3. 検索バーを取得し、検索ワードを入力した後に検索を行います
- 4. 検索結果画面をスクリーンショットします
- 補足
- – Seleniumは処理が終了すると自動でブラウザを閉じるので、
本稿では閉じないような処理を意図的に含めています
- – ブラウザが起動しない場合、ブラウザとドライバーのバージョンが一致していない可能性が高いです
- – Seleniumは処理が終了すると自動でブラウザを閉じるので、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
from selenium.webdriver import Chrome, Edge from selenium.webdriver.remote.webdriver import WebDriver from selenium.webdriver.common.by import By # 利用するブラウザー browser = "chrome" # Microsoft Edge を利用する場合は以下をコメントを外す # browser = "edge" # ブラウザ(ドライバー)を起動します driver: WebDriver if browser == "chrome": driver = Chrome("drivers/chromedriver.exe") elif browser == "edge": edge_options = {"use_chromium": True} driver = Edge("drivers/msedgedriver.exe", capabilities=edge_options) # 要素検索待ち時間 driver.implicitly_wait(15) # Google検索のURLを開きます driver.get("https://www.google.com/") # Googleの検索バーを取得 search_box = driver.find_element(By.NAME, "q") # Googleの検索バーへ文字を入力 search_box.send_keys("ニフティ") # エンターキーを押すの同義 search_box.submit() # 検索結果画面のスクリーンショットを取ります driver.get_screenshot_as_file("search_result.png") input("エンターを押すと終了します。") |
動作デモ実行結果
TIPS
- HTML要素を取得する時は driver.find_element を利用しますが、By.○○は以下のバリエーションがあります- NAME, ID, CLASS_NAME, LINK_TEXT, TAG_NAME, XPATH
- – driver.find_element で取得する場合、先頭の1つが取得できます
- – driver.find_elements で取得する場合、該当の全ての要素を取得します
- 存在しない要素を指定するとエラーが発生して終了します
- – driver.find_elements という関数を使い、要素があった場合取得すると解決します
- – 動作デモでは省略しましたが、要素を取得する場合は以下のように書くのが好ましいです
- – 以下の例では、検索ボックスが見つかれば入力を行うようになります
|
1 2 3 4 5 6 7 8 9 |
# Googleの検索バーを検索 find_search_box = driver.find_elements(By.NAME, "q") if len(find_search_box) > 0: # 検索にヒットした1件目の要素を取得 search_box = find_search_box[0] # Googleの検索バーへ文字を入力 search_box.send_keys("ニフティ") # エンターキーを押すの同義 search_box.submit() |
- 要素はページが読み込まれた瞬間に存在するとは限りません
- – 要素の表示が遅れると取得できない為、要素が表示されるまで取得を待たせる必要があります
- – プログラム内の driver.implicitly_wait(秒) は要素が表示されるまで最大 秒 待たせる関数です
- 取得された要素でよく使われる関数は以下の通りです
- – element.send_keys(“入力値”) : 要素に対して文字列を入力します
- – element.click() : 要素をクリックします
- – element.clear() : 要素がテキストボックス等であれば、内容を消去します
- 自動操作のスクリプトを組み立てる際、操作命令の順序を間違えても実行される為、
正しい操作が行われるように試行錯誤する必要があります- – 画面の状態や入力のタイミングが食い違い、人力での操作より思い通りになりません
- – 動的(特に非同期処理)なWebアプリとは相性が悪く、手動の方が早い場合もあります
- Selenide という Selenium をラッピングした非同期処理にも対応可能なフレームワークもあります
- – Selenium よりも簡素なコードで自動テストを行うことが出来ます
- – 対応している言語は Java のみとなります
(Selenium は Python の他に Ruby, Javascript 等複数の言語で扱うことが出来ます) - – Selenium に比べて多くの事前準備が必要ですが、一度揃えば強力なフレームワークです
- – インストールしてすぐに扱えるという手軽さから Selenium を推しますが、
もし Java が得意でしたら、ぜひこちらもお試しください
バックエンド開発者視点から
本稿の自動ブラウジングはWebアプリケーション内のフロントエンド、バックエンドの結合テストに利用される手段の一つです。
フロントエンドとバックエンドの担当者が異なる場合は、
主にフロントエンドの作りに対して、意識の擦り合わせが必要となってきます。
Seleniumにて画面上の要素を取得する場合は、該当の箇所を明示的に指定する必要があります。
なので、HTML上でIDやNameを入れるとテストしやすくなります。
無くてもXPathを取得すれば使えますが、画面の構成が変わってしまうと再びXPathを取得しなおさなければなりません。
だからIDやNameを入れる必要があったのですね。
(XPath: HTML上の要素への絶対パス)








